Claude Mythos Preview는 Anthropic의 현재 플래그십 Opus 4.6을 크게 상회하는 성능을 가진 모델이다. 코드명 'Capybara'로 개발됐으며, Opus 위에 새로운 성능 티어를 형성한다. 공식 벤치마크 기준으로 SWE-bench Verified 93.9%(Opus 4.6은 80.8%), SWE-bench Pro 77.8%(GPT-5.3의 ~56.8% 대비), USAMO 97.6%를 기록했다. 실제 소프트웨어 엔지니어링 과제를 기준으로 19번 중 거의 18번을 정확히 해결하는 수준이다.
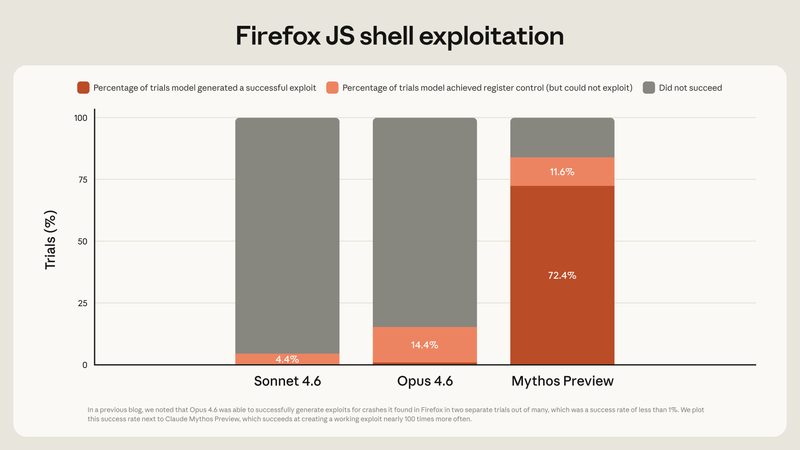
주목할 점은 보안 영역이다. 내부 테스트에서 모든 주요 OS(Windows, macOS, Linux)와 웹 브라우저에서 제로데이 취약점을 자율적으로 발견·익스플로잇했다. OpenBSD의 27년 된 버그, FFmpeg H.264 코덱의 16년 된 취약점을 찾아냈으며, 전문 침투 테스터가 수 주가 걸릴 익스플로잇 코드를 몇 시간 내에 작성했다. 이 결과가 Anthropic이 일반 공개를 보류한 핵심 이유다.
Claude Mythos Preview 완전 분석 — SWE-bench 93.9%, Project Glasswing, 개발자 보안 대응 가이드
Claude Mythos Preview 는 Anthropic이 2026년 4월 7일 공식 발표했지만 일반 공개를 거부한 프론티어 모델이다. SWE-bench 93.9%, USAMO 97.6%를 기록하고 모든 주요 OS와 브라우저에서 제로데이 취약점을 자율 발견한 이 모델은, 보안 위험을 이유로 'Project Glasswing' 컨소시엄 12개 파트너사에만 제한 접근을 허용한다.
by Lee
Claude Mythos Preview는 Anthropic이 2026년 4월 7일 공식 발표했지만 일반 공개를 거부한 프론티어 모델이다. SWE-bench 93.9%, USAMO 97.6%를 기록하고 모든 주요 OS와 브라우저에서 제로데이 취약점을 자율 발견한 이 모델은, 보안 위험을 이유로 'Project Glasswing' 컨소시엄 12개 파트너사에만 제한 접근을 허용한다. 이 글은 AI/LLM을 실무에 적용하는 개발자, 보안팀, 엔지니어링 리더를 대상으로 Mythos Preview의 실제 성능과 제한 출시 결정의 배경, 그리고 접근 권한 없이도 지금 당장 해야 할 실무 대응을 정리한다.
Claude Mythos Preview란 무엇인가

SWE-bench 93.9% — 수치가 개발자에게 의미하는 것
SWE-bench는 GitHub 이슈를 실제로 해결하는 능력을 측정하는 벤치마크다. '코드를 생성할 수 있는가'가 아니라 '실제 대규모 코드베이스에서 버그를 찾아 패치를 만들 수 있는가'를 테스트한다. 93.9%라는 수치는 100개의 실제 버그 리포트 중 94개를 올바른 코드 변경으로 해결한다는 뜻이다.
실무 적용 관점에서 이 수치의 함의는 세 가지다.
첫째, 코드 리뷰 자동화의 품질 임계점이 달라진다. 기존 모델들이 명확한 버그 수정은 잘 처리하지만 복잡한 비즈니스 로직 결함에서 틀리는 경우가 많았다면, 93.9% 수준에서는 '에이전트가 놓칠 수 있다'는 가정으로 설계된 안전망이 다시 설계돼야 한다.
둘째, 주니어 개발자 역할의 경계가 다시 그어진다. Pragmatic Engineer 설문(3310편)에서 주니어 채용이 줄고 있다는 데이터가 있었다. Mythos 수준에서는 단순 버그 수정, 기능 추가 PR, 테스트 작성 같은 작업이 대부분 자동화 가능해진다.
셋째, 벤치마크와 프로덕션 성능의 간극은 여전히 존재한다. SWE-bench 이슈는 명확히 정의된 버그다. 실제 프로덕션에서는 모호한 요구사항, 레거시 아키텍처 의존성, 팀 컨텍스트가 필요한 판단이 포함된다. 93.9%는 최상의 조건에서의 수치다.
실무 적용 관점에서 이 수치의 함의는 세 가지다.
첫째, 코드 리뷰 자동화의 품질 임계점이 달라진다. 기존 모델들이 명확한 버그 수정은 잘 처리하지만 복잡한 비즈니스 로직 결함에서 틀리는 경우가 많았다면, 93.9% 수준에서는 '에이전트가 놓칠 수 있다'는 가정으로 설계된 안전망이 다시 설계돼야 한다.
둘째, 주니어 개발자 역할의 경계가 다시 그어진다. Pragmatic Engineer 설문(3310편)에서 주니어 채용이 줄고 있다는 데이터가 있었다. Mythos 수준에서는 단순 버그 수정, 기능 추가 PR, 테스트 작성 같은 작업이 대부분 자동화 가능해진다.
셋째, 벤치마크와 프로덕션 성능의 간극은 여전히 존재한다. SWE-bench 이슈는 명확히 정의된 버그다. 실제 프로덕션에서는 모호한 요구사항, 레거시 아키텍처 의존성, 팀 컨텍스트가 필요한 판단이 포함된다. 93.9%는 최상의 조건에서의 수치다.
Project Glasswing — 왜 일반 공개를 거부했나
Anthropic은 Mythos Preview를 일반 API로 제공하지 않고, Project Glasswing이라는 컨소시엄 프레임워크를 통해 제한 접근을 허용한다. 참여 기관은 AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, Linux Foundation, Microsoft, NVIDIA, Palo Alto Networks 등 약 12개 핵심 파트너와 추가 40개 내외의 핵심 소프트웨어 인프라 유지 조직이다.
Anthropic의 공식 프레임은 이렇다: '이 모델이 악의적 행위자의 손에 들어가기 전에, 방어자들이 먼저 취약점을 찾고 패치할 시간을 줘야 한다.' 프로젝트 예산은 $1억 달러(사용 크레딧)이며, 오픈소스 보안 조직에 $400만 달러 직접 기부가 포함된다.
비판적 시각도 존재한다. Mythos Preview의 가격은 입력 $25/M 토큰, 출력 $125/M 토큰으로 Opus 4.6의 5배, GPT-5.3($1.75/$14) 대비 10~15배 높다. 일부 분석가는 '공개하기 너무 위험하다'는 프레임이 실제로는 컴퓨팅 용량 제약을 가리기 위한 것일 수 있다고 본다. Anthropic의 과거 사례에서 대규모 수요가 몰렸을 때 모델 품질 저하와 사용 한도 문제가 반복됐기 때문이다.
Anthropic의 공식 프레임은 이렇다: '이 모델이 악의적 행위자의 손에 들어가기 전에, 방어자들이 먼저 취약점을 찾고 패치할 시간을 줘야 한다.' 프로젝트 예산은 $1억 달러(사용 크레딧)이며, 오픈소스 보안 조직에 $400만 달러 직접 기부가 포함된다.
비판적 시각도 존재한다. Mythos Preview의 가격은 입력 $25/M 토큰, 출력 $125/M 토큰으로 Opus 4.6의 5배, GPT-5.3($1.75/$14) 대비 10~15배 높다. 일부 분석가는 '공개하기 너무 위험하다'는 프레임이 실제로는 컴퓨팅 용량 제약을 가리기 위한 것일 수 있다고 본다. Anthropic의 과거 사례에서 대규모 수요가 몰렸을 때 모델 품질 저하와 사용 한도 문제가 반복됐기 때문이다.
Project Glasswing 참여 조건
현재 접근은 초대제다. 'critical software infrastructure'를 운영하거나 구축하는 조직이 대상이다. Anthropic의 안전 기준 평가 후 접근이 부여된다. 개인 개발자 또는 소규모 스타트업의 일반 API 접근 일정은 공개되지 않았다.
현재 접근은 초대제다. 'critical software infrastructure'를 운영하거나 구축하는 조직이 대상이다. Anthropic의 안전 기준 평가 후 접근이 부여된다. 개인 개발자 또는 소규모 스타트업의 일반 API 접근 일정은 공개되지 않았다.

취약점 발견-악용 타임라인 압축 — 보안팀 실무 대응
보안 전문가들이 Mythos Preview에서 가장 주목하는 것은 단순 성능이 아니라 '발견에서 익스플로잇까지의 시간 압축'이다. 역사적으로 취약점이 존재해도 악의적 행위자가 이를 발견하고 익스플로잇 코드를 만들기까지 며칠에서 몇 달의 시간이 있었다. 이 시간이 방어자가 패치를 배포할 창이었다. Mythos 수준의 모델이 일반화되면 이 창이 시간 단위로 좁혀질 수 있다.
Glasswing 외부에 있는 개발팀이 지금 해야 할 실무 행동:
1. 침투 테스트 주기 단축: 연 1~2회 외부 침투 테스트를 분기 단위로 높이거나, AI 기반 자동화 취약점 스캐닝 도입을 검토한다.
2. 고위험 CVE 패치 우선순위 상향: CVSS 7.0+ 취약점을 현재보다 빠르게 패치해야 한다. '다음 릴리즈 때 포함'하는 방식이 통하지 않는다.
3. 공급망 의존성 스캔 강화: npm, pip, Docker 이미지 등 의존성의 알려진 취약점을 CI/CD 파이프라인에서 자동 차단하는 단계가 필수화된다.
4. 제로데이 가정 아키텍처: '패치됐으니 안전하다'가 아니라 '언제든 익스플로잇될 수 있다'를 전제한 최소 권한 원칙(Least Privilege), 네트워크 세그멘테이션, 실시간 이상 탐지 도입이 실무에서 선택이 아닌 필수가 된다.
Glasswing 외부에 있는 개발팀이 지금 해야 할 실무 행동:
1. 침투 테스트 주기 단축: 연 1~2회 외부 침투 테스트를 분기 단위로 높이거나, AI 기반 자동화 취약점 스캐닝 도입을 검토한다.
2. 고위험 CVE 패치 우선순위 상향: CVSS 7.0+ 취약점을 현재보다 빠르게 패치해야 한다. '다음 릴리즈 때 포함'하는 방식이 통하지 않는다.
3. 공급망 의존성 스캔 강화: npm, pip, Docker 이미지 등 의존성의 알려진 취약점을 CI/CD 파이프라인에서 자동 차단하는 단계가 필수화된다.
4. 제로데이 가정 아키텍처: '패치됐으니 안전하다'가 아니라 '언제든 익스플로잇될 수 있다'를 전제한 최소 권한 원칙(Least Privilege), 네트워크 세그멘테이션, 실시간 이상 탐지 도입이 실무에서 선택이 아닌 필수가 된다.
가격 구조와 언제 일반 공개가 될까
현재 공개된 Mythos Preview 가격은 입력 $25/M 토큰, 출력 $125/M 토큰이다. 비교하면:
일반 공개 일정은 미정이다. Anthropic은 'Project Glasswing 파트너들이 취약점을 충분히 패치한 이후'를 전제 조건으로 제시했지만 구체적 기간을 명시하지 않았다. 업계에서는 6~12개월 내 단계적 공개를 예상하는 시각이 많다. 다만 이 시점에 현재 가격이 유지될 가능성은 낮고, 성능 포지셔닝에 따라 Opus 급 가격으로 조정될 가능성이 있다.
| 모델 | 입력 ($/M) | 출력 ($/M) | SWE-bench |
|---|---|---|---|
| Mythos Preview | $25 | $125 | 93.9% |
| Claude Opus 4.6 | $5 | $25 | 80.8% |
| GPT-5.3 | $1.75 | $14 | ~56.8% |
| Gemini 3.1 Pro | $2 | $12 | - |
일반 공개 일정은 미정이다. Anthropic은 'Project Glasswing 파트너들이 취약점을 충분히 패치한 이후'를 전제 조건으로 제시했지만 구체적 기간을 명시하지 않았다. 업계에서는 6~12개월 내 단계적 공개를 예상하는 시각이 많다. 다만 이 시점에 현재 가격이 유지될 가능성은 낮고, 성능 포지셔닝에 따라 Opus 급 가격으로 조정될 가능성이 있다.
실무 관점 해석 — 지금 당장 취해야 할 3가지 행동
Mythos Preview에 직접 접근할 수 없더라도 이 발표는 지금 실무에 세 가지 행동을 요구한다.
행동 1 — 보안 스택 점검 (이번 주)
현재 의존하는 오픈소스 라이브러리의 CVE 현황을 확인하라.
행동 2 — 코드 리뷰 파이프라인 재평가 (이번 달)
현재 AI 코드 리뷰 도구가 보안 관점에서 충분한지 검토하라. GitHub Copilot Security, Snyk Code, CodeRabbit 같은 도구들이 Mythos 수준의 취약점 발견 능력을 갖추지 못했다면, '에이전트가 리뷰했으니 안전하다'는 가정을 재검토해야 한다.
행동 3 — 채용/역할 재정의 준비 (이번 분기)
SWE-bench 93.9% 모델이 일반화되면 코드 생성·버그 수정 역할의 가치가 더 빠르게 변한다. 아키텍처 설계, 보안 판단, 비즈니스 로직 명세화, AI 결과물 검증 능력이 더 중요해진다. 이 전환을 지금 준비해야 한다.
행동 1 — 보안 스택 점검 (이번 주)
현재 의존하는 오픈소스 라이브러리의 CVE 현황을 확인하라.
npm audit, pip-audit, trivy image 명령어로 지금 당장 스캔할 수 있다. AI 기반 취약점 발견이 가속화된다는 것은 패치 시간이 없어진다는 뜻이다.행동 2 — 코드 리뷰 파이프라인 재평가 (이번 달)
현재 AI 코드 리뷰 도구가 보안 관점에서 충분한지 검토하라. GitHub Copilot Security, Snyk Code, CodeRabbit 같은 도구들이 Mythos 수준의 취약점 발견 능력을 갖추지 못했다면, '에이전트가 리뷰했으니 안전하다'는 가정을 재검토해야 한다.
행동 3 — 채용/역할 재정의 준비 (이번 분기)
SWE-bench 93.9% 모델이 일반화되면 코드 생성·버그 수정 역할의 가치가 더 빠르게 변한다. 아키텍처 설계, 보안 판단, 비즈니스 로직 명세화, AI 결과물 검증 능력이 더 중요해진다. 이 전환을 지금 준비해야 한다.
Anthropic 공식 발표 원문
Claude Mythos Preview 공식 발표: red.anthropic.com/2026/mythos-preview/
Simon Willison의 Project Glasswing 분석: simonwillison.net/2026/Apr/7/project-glasswing/
Foreign Policy — 사이버보안 함의: foreignpolicy.com
Claude Mythos Preview 공식 발표: red.anthropic.com/2026/mythos-preview/
Simon Willison의 Project Glasswing 분석: simonwillison.net/2026/Apr/7/project-glasswing/
Foreign Policy — 사이버보안 함의: foreignpolicy.com
Claude MythosAnthropicProject GlasswingSWE-benchAI 보안취약점프론티어 모델LLM보안사이버보안
관련 도구
Claude CodeAI 코딩 도구
CLI 기반 AI 에이전트 코딩 도구. 터미널에서 전체 프로젝트를 자율적으로 생성·수정·실행한다.
Claude Opus 4.8LLM 모델
Anthropic 최상위 플래그십 (2026, 최신). SWE-bench Verified 88.6%로 코딩 ...
Claude Sonnet 4.6LLM 모델
2026년 최고 가성비 API 모델. Opus 4.8 품질에 1/5 가격, 1M 컨텍스트 표준가 적용.
Claude Haiku 4.5LLM 모델
Anthropic 최속·최경량 모델 (2025.10). Sonnet 4 수준 코딩 성능을 $1/1M 입력가,...
EXPLORE / AI/LLM
이어서 읽어보기

AI/LLMAnthropic Claude Mythos 유출 — Opus 위의 새로운 티어, 사이버보안 능력이 방어를 추월한다2026-03-30

AI/LLMQwen3.6-Plus 완전 분석 — 1M 컨텍스트, SWE-bench 78.8, 에이전틱 코딩 AI의 새 기준2026-04-15

AI/LLMxAI Grok 4.3 개발자 가이드 — Speech-to-Text·Text-to-Speech API 실전 활용2026-04-24
AI/LLMClaude Opus 4.7 완전 분석 — xhigh 노력 레벨, Task Budget, 토크나이저 마이그레이션 가이드2026-04-17