LLM 인퍼런스 속도를 2~5배 높이는 법 — Speculative Decoding과 KV Cache 최적화 실전 가이드
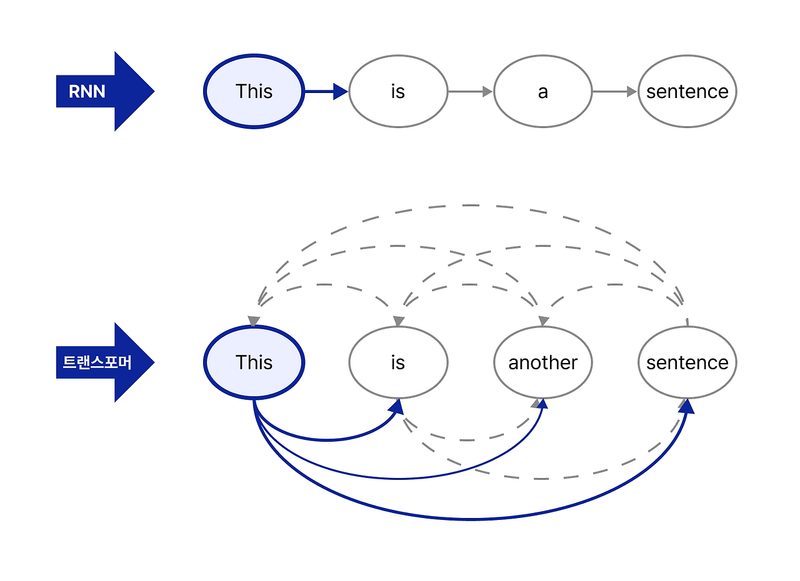
LLM을 서비스에 붙였는데 응답이 너무 느리다면, 가장 먼저 확인해야 할 것은 인퍼런스 최적화다. 모델을 바꾸지 않고도 Speculative Decoding과 KV Cache 최적화만으로 2~5배의 속도 향상이 가능하다. LLM은 텍스트를 한 토큰씩 생성한다. 각 토큰을 생성할 때마다 전체 모델을 한 번씩 통과(forward pass)해야 한다.
LLM을 서비스에 붙였는데 응답이 너무 느리다면, 가장 먼저 확인해야 할 것은 인퍼런스 최적화다. 모델을 바꾸지 않고도 Speculative Decoding과 KV Cache 최적화만으로 2~5배의 속도 향상이 가능하다. 2026년 초 AWS가 P-EAGLE을 vLLM v0.16.0에 공식 통합하면서 이 기술이 연구 단계에서 프로덕션 표준으로 진입했다.
이 글은 LLM 인퍼런스를 직접 서빙하는 백엔드·MLOps 개발자를 위한 실전 가이드다. Speculative Decoding의 원리, KV Cache 최적화 3가지 기법, vLLM·SGLang·TensorRT-LLM 서빙 엔진 선택 기준까지 코드 중심으로 정리한다.
LLM 인퍼런스가 느린 이유
LLM은 텍스트를 한 토큰씩 생성한다. 각 토큰을 생성할 때마다 전체 모델을 한 번씩 통과(forward pass)해야 한다. 1,000 토큰짜리 응답이면 forward pass가 1,000번이다. 이게 LLM이 느린 근본 원인이다.
병목은 두 곳에 있다:
메모리 대역폭 병목(Memory-bound): GPU 연산 능력이 있어도 모델 가중치를 GPU 메모리에서 읽어오는 속도가 병목. 특히 배치 크기가 작을 때(동시 요청 수가 적을 때) 두드러진다. Speculative Decoding이 해결하는 영역.
KV Cache 메모리 부족: 이전 토큰의 Key-Value 계산 결과를 캐시해두는 KV Cache가 넘치면 요청을 처리하지 못하고 대기한다. PagedAttention과 KV Cache 오프로딩이 해결하는 영역.
LLM 인퍼런스의 두 가지 병목: 메모리 대역폭(왼쪽)과 KV Cache 메모리(오른쪽)
Speculative Decoding — 소형 모델이 초안, 대형 모델이 검증
Speculative Decoding(추측 디코딩)의 핵심 아이디어는 간단하다: 작고 빠른 Draft 모델이 여러 토큰을 미리 생성하고, 크고 정확한 Target 모델이 한 번에 병렬로 검증한다.
단계별 동작:
Draft 모델(예: Llama 3.2 1B)이 γ개 토큰을 순차 생성 (매우 빠름)
Target 모델(예: Llama 3.1 70B)이 γ+1개 위치를 한 번의 forward pass로 동시 검증
검증 통과된 토큰은 채택, 불일치한 토큰부터 뒤를 버리고 재생성
Target 모델의 출력 분포를 유지하면서 최소 1개 토큰은 항상 생성되므로 correctness 보장
속도 향상 원리: Target 모델 1 forward pass에서 여러 토큰을 동시에 검증하므로, 실효 처리량(throughput)이 Draft 모델의 예측 정확도에 비례해 올라간다. 예측 정확도가 80%면 이론적으로 최대 5x 속도 향상이 가능하다.
from vllm import LLM, SamplingParams
# Draft 모델을 지정해 Speculative Decoding 활성화
llm = LLM(
model="meta-llama/Llama-3.1-70B-Instruct", # Target 모델
speculative_model="meta-llama/Llama-3.2-1B", # Draft 모델
num_speculative_tokens=5, # 한 번에 추측할 토큰 수 (γ)
speculative_max_model_len=2048, # Draft 모델 최대 길이
tensor_parallel_size=4, # GPU 4장 사용
)
sampling_params = SamplingParams(temperature=0.8, max_tokens=512)
output = llm.generate("설명해줘: Speculative Decoding이란", sampling_params)
print(output[0].outputs[0].text)
P-EAGLE — vLLM v0.16.0에 통합된 병렬 Speculative Decoding
기존 Speculative Decoding의 한계는 Draft 모델 자체도 순차적으로 토큰을 생성한다는 점이다. P-EAGLE(Parallel Eagle)은 AWS와 학계가 공동 개발해 2026년 초 vLLM v0.16.0에 공식 통합한 알고리즘으로, Draft 단계 자체를 병렬화해 이 한계를 돌파한다.
P-EAGLE의 핵심 차이:
기존 Speculative Decoding: Draft 모델이 γ개 토큰을 순차 생성 → Target 모델이 병렬 검증
P-EAGLE: Draft 토큰을 단일 forward pass로 병렬 생성 → Target 모델이 병렬 검증
결과적으로 Draft 단계의 지연이 거의 없어진다. AWS 벤치마크에서 Llama 3.1 70B + P-EAGLE 조합으로 낮은 동시 요청 환경(batch size 1~4)에서 기존 대비 2.4~5.2x throughput 향상을 달성했다.
# vLLM v0.16.0+ 필요
pip install vllm>=0.16.0
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.1-70B-Instruct",
speculative_model="eagle", # P-EAGLE 활성화 키워드
num_speculative_tokens=6,
speculative_draft_tensor_parallel_size=1,
tensor_parallel_size=4,
)
# 또는 CLI로 서버 실행 시
# vllm serve meta-llama/Llama-3.1-70B-Instruct \
# --speculative-model eagle \
# --num-speculative-tokens 6 \
# --tensor-parallel-size 4
P-EAGLE: Draft 단계를 단일 forward pass로 병렬화해 지연을 최소화한다 (출처: AWS ML Blog)
KV Cache 최적화 3가지 기법
Speculative Decoding이 속도를 높인다면, KV Cache 최적화는 동시 처리 가능한 요청 수(throughput)와 더 긴 컨텍스트 처리 능력을 높인다.
기법 1 — PagedAttention (vLLM 기본)
운영체제의 가상 메모리 페이징 개념을 KV Cache에 적용한 방법이다. 기존에는 요청마다 연속된 GPU 메모리 블록을 예약해뒀다가 낭비가 심했다. PagedAttention은 비연속 메모리 블록을 논리적으로 연결해 메모리 낭비를 거의 없앤다. vLLM 기본으로 적용되어 있으므로 별도 설정 없이 효과를 본다.
기법 2 — NVFP4 양자화 (H100/H200 네이티브)
NVIDIA H100/H200에서 FP4 연산을 하드웨어 레벨에서 지원한다. KV Cache를 FP16 대신 FP4로 저장하면 메모리 사용량이 4분의 1로 줄어든다. 동시 처리 가능한 요청 수가 그만큼 늘어난다.
기법 3 — LMCache (KV Cache 오프로딩)
자주 반복되는 프롬프트의 KV Cache를 GPU 메모리에서 CPU 메모리나 디스크로 오프로딩해두고 재사용하는 방법이다. RAG 시스템처럼 동일한 문서를 반복적으로 참조하는 경우 GPU 메모리 절약이 크다.
서빙 엔진 선택 가이드 — vLLM vs SGLang vs TensorRT-LLM
최적화 기법을 선택했다면, 어떤 서빙 엔진에서 실행할지도 결정해야 한다. 2026년 기준 주요 3가지 엔진의 실무 차이를 정리한다.