Gemini 3 Flash 완전 분석 — 속도·코딩 성능·API 가격, 개발자 실전 가이드
Google DeepMind가 출시한 Gemini 3 Flash의 SWE-bench 78%, GPQA Diamond 90.4% 벤치마크 분석과 2.5 Flash 대비 요금 비교, Python SDK·Gemini CLI·Vertex AI 실전 코드, 그리고 언제 Flash 티어를 업그레이드해야 하는지 판단 기준을 정리한다.
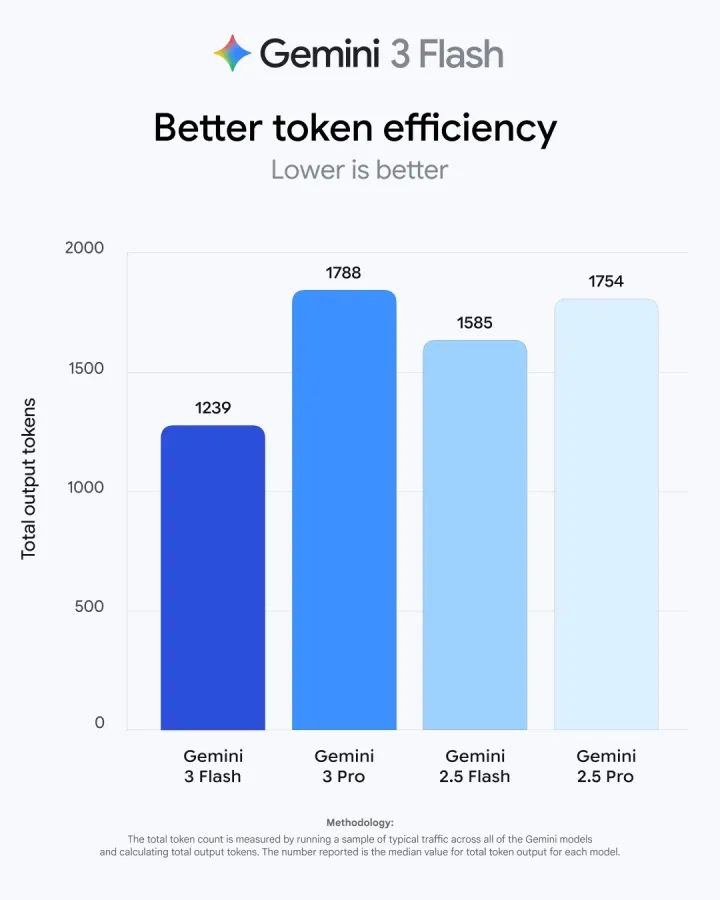
Gemini 3 Flash는 Google이 2026년 출시한 고속·저비용 최적화 모델이다. SWE-bench 코딩 벤치마크에서 Gemini 2.5 Pro를 앞지르면서 동시에 처리 속도는 3배 빠르다. API 가격은 입력 토큰당 $0.075/M으로 Gemini 2.5 Flash 대비 25% 인하됐다.
이 글이 필요한 사람: Gemini API로 AI 기능을 개발 중인 백엔드·풀스택 개발자, LLM 비용을 최적화하려는 스타트업 엔지니어, Google AI Studio·Vertex AI 도입을 검토 중인 팀, Gemini 2.5에서 업그레이드를 고민하는 개발자.
Gemini 3 Flash는 Google DeepMind가 2026년 출시한 Gemini 3 모델 패밀리 중 속도·비용 최적화 라인이다. Gemini 3 Pro(플래그십)의 추론 능력을 기반으로, 프로덕션 규모의 API 트래픽을 감당하도록 설계됐다.
Google은 출시 시 "Gemini 3 Flash가 Gemini 2.5 Pro보다 3배 빠르면서 코딩 벤치마크에서는 앞선다"고 발표했다. SWE-bench 78% 달성은 당시 공개 모델 중 상위 수준이다.
Gemini 3 Flash 패밀리는 세 가지 티어로 구성된다. Gemini 3 Flash(메인 프로덕션 워크로드), Gemini 3.1 Flash(추론 정밀도 개선 버전), Gemini 3.1 Flash Lite(최저 비용, 고볼륨 단순 태스크). Google AI Studio, Vertex AI, Gemini CLI 등 구글 개발 채널 전체에서 접근 가능하다.
Gemini 3 Flash는 2.5 Pro보다 SWE-bench 성능이 높으면서 가격은 17배 저렴하다. 출처: Google AI 공식 발표 (2026.04)
Python SDK 퀵스타트
Google AI Studio에서 API 키를 발급받은 후 google-generativeai SDK로 바로 시작할 수 있다. 2026년 4월 기준 SDK 버전은 0.8.x 이상을 권장한다.
SDK 설치
pip install google-generativeai --upgrade
기본 텍스트 생성
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash")
response = model.generate_content(
"Python asyncio의 이벤트 루프 동작 원리를 개발자에게 설명해줘",
generation_config=genai.types.GenerationConfig(
temperature=0.7,
max_output_tokens=2048,
)
)
print(response.text)
멀티모달 — 이미지·PDF 분석
Gemini 3 Flash는 텍스트 외에 이미지, PDF, 영상 분석을 지원한다. 1M 토큰 컨텍스트 윈도우 덕분에 수백 페이지 문서를 한 번에 처리할 수 있다. 코드 스크린샷을 분석하거나 ERD 다이어그램에서 SQL을 생성하는 용도로 실무에서 많이 쓰인다.
이미지 분석 — 코드 스크린샷 리뷰
import google.generativeai as genai
from PIL import Image
import pathlib
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash")
# 이미지 파일 로드
image = Image.open("code_screenshot.png")
response = model.generate_content([
image,
"이 코드의 버그를 찾아주고, 수정 방법을 알려줘"
])
print(response.text)
Gemini 3 Flash의 멀티모달 기능. 코드 스크린샷, ERD 다이어그램, PDF 문서를 텍스트와 함께 분석할 수 있다.
스트리밍 채팅 세션 구현
프로덕션 앱에서는 응답을 스트리밍으로 받아 사용자에게 즉시 표시하는 것이 중요하다. Gemini SDK의 generate_content_stream으로 토큰이 생성되는 대로 받아볼 수 있다.
멀티턴 채팅 + 스트리밍
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash")
# 멀티턴 채팅 세션
chat = model.start_chat(history=[])
# 스트리밍으로 응답 받기
response = chat.send_message(
"FastAPI로 JWT 인증 미들웨어를 구현하는 방법을 알려줘",
stream=True
)
for chunk in response:
print(chunk.text, end="", flush=True)
# 두 번째 메시지 — 이전 대화 컨텍스트 유지
response2 = chat.send_message(
"Refresh Token 처리는 어떻게 해?",
stream=True
)
for chunk in response2:
print(chunk.text, end="", flush=True)
Function Calling — 외부 도구 연동
Gemini 3 Flash는 OpenAI 스타일의 function calling을 지원한다. 데이터베이스 조회, 외부 API 호출, 계산 도구 등을 정의하면 모델이 필요할 때 자율적으로 호출한다.
Function Calling 예시
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
# 도구 정의
tools = [
{
"function_declarations": [
{
"name": "get_stock_price",
"description": "주식 종목의 현재 가격을 조회합니다",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "종목 코드 (예: AAPL, GOOGL)"
}
},
"required": ["symbol"]
}
}
]
}
]
model = genai.GenerativeModel("gemini-3-flash", tools=tools)
response = model.generate_content("삼성전자 현재 주가 알려줘")
# 함수 호출 여부 확인
if response.candidates[0].content.parts[0].function_call:
fc = response.candidates[0].content.parts[0].function_call
print(f"호출 함수: {fc.name}, 인수: {dict(fc.args)}")
Gemini CLI — 터미널에서 바로 사용
2026년 4월 기준 Google은 Gemini CLI를 정식 릴리즈했다. Claude Code처럼 터미널에서 대화하며 파일을 수정하고, 코드를 실행하고, 검색까지 할 수 있다. 기본 모델은 Gemini 3 Flash가 사용된다.
Gemini CLI 설치 및 시작
# Node.js 18+ 필요
npm install -g @google/gemini-cli
# 인증 (Google 계정으로 로그인)
gemini auth
# 기본 사용
gemini "이 Python 파일의 테스트를 작성해줘"
# 파일 첨부
gemini -f main.py "이 코드 리뷰해줘"
# 대화 모드
gemini --chat
Gemini CLI는 터미널에서 대화·파일 분석·코드 실행을 지원한다. 기본 모델로 Gemini 3 Flash를 사용한다.
언제 Gemini 3 Flash를 쓰고, 언제 Pro가 필요한가
Gemini 3 Flash를 선택해야 하는 경우
API 호출량이 많아 비용 최적화가 중요한 경우 (Flash가 Pro 대비 최대 17배 저렴)
코딩 자동화, PR 리뷰, 코드 생성 등 SWE-bench 성능이 중요한 워크플로우
응답 속도가 핵심인 실시간 앱 (Flash가 3배 빠름)
일반 채팅, 문서 요약, 번역 등 표준 언어 태스크
Gemini 3 Pro가 필요한 경우
수학적 추론, 복잡한 멀티스텝 분석 태스크
과학·연구 분야 고도 정확도가 필요한 경우
Flash 결과물이 일관성이 없거나 정확도가 부족할 때
비용 계산 예시: 월 10M 입력 토큰, 2M 출력 토큰 기준 — Gemini 2.5 Pro는 약 $21, Gemini 3 Flash는 약 $1.35. 코딩 태스크에서 성능 차이가 크지 않다면 Flash가 압도적으로 유리하다.