딥시크(DeepSeek)가 2026년 4월 24일 V4 모델을 MIT 라이선스로 공개했다. V4-Pro는 1.6조 파라미터(MoE 구조, 49B 활성화), V4-Flash는 284B 파라미터. 동시에 창업자 량원펑(Liang Wenfeng)이 100억 달러(약 70억 위안) 투자 유치를 앞두고 "AGI 최우선, 상용화는 2순위"를 공개 선언했다. V4-Pro의 출력 비용은 1M 토큰당 $3.48 — 오픈AI의 12분의 1, 앤트로픽의 7분의 1이다. 이 숫자가 의미하는 것과 개발자 관점의 실무 판단 기준을 정리했다.
이 글이 필요한 분- LLM API 비용을 줄이려는 개발자·스타트업
- 오픈소스 LLM 셀프호스팅을 검토 중인 분
- 딥시크 V4가 클로즈드 모델 대비 어느 수준인지 판단해야 하는 분
- AI 모델 경쟁 구도가 자신의 아키텍처 선택에 영향을 주는지 파악하려는 분
2026년 4월 24일, 딥시크는 V4 시리즈를 Hugging Face에 공개했다. MIT 라이선스를 적용해 상업적 사용, 파인튜닝, 재배포가 모두 허용된다.
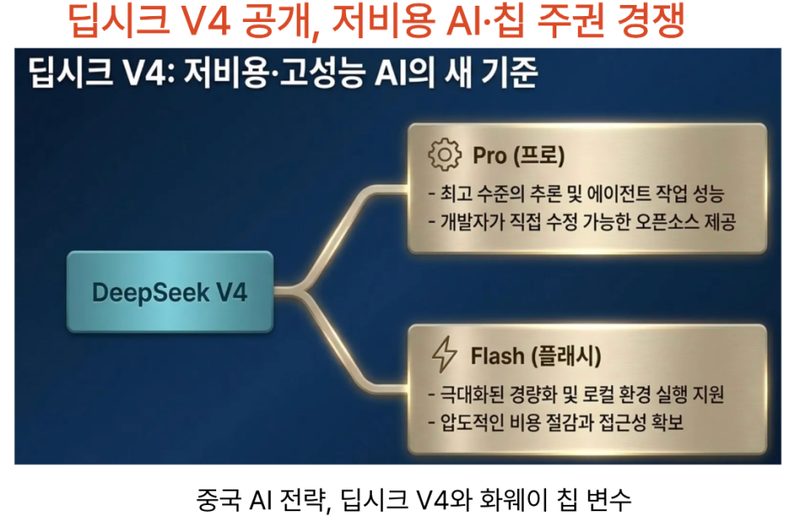
V4-Pro: 1.6조(1.6T) 파라미터의 MoE(Mixture-of-Experts) 모델. 실제로 추론할 때 활성화되는 파라미터는 49B다. 컨텍스트 윈도우는 100만 토큰(1M). 에이전틱 코딩 벤치마크에서 GPT-5.5, 클로드 Opus 4.7과 비슷한 수준을 기록했다고 CNBC와 Lambda AI 분석 블로그가 보고했다.
V4-Flash: 284B 파라미터(13B 활성화). V4-Pro의 경량 버전으로, 대량 처리·저지연 작업에 특화된 포지션이다. 컨텍스트 윈도우는 동일하게 1M 토큰.
두 모델 모두 하이브리드 어텐션 메커니즘을 쓴다. 압축 희소 어텐션(CSA)과 강압축 어텐션(HCA)을 결합해 긴 컨텍스트 처리 효율을 높였다고 공식 API 문서(DeepSeek API Docs)에서 밝혔다.
딥시크의 가격 경쟁력은 수치가 직접 말한다. 포춘(Fortune)과 Lambda AI의 보도를 기준으로 정리했다.
V4-Flash를 쓰면 클로드 Opus 4.7 대비 출력 비용이 약 90분의 1이다. 대량 처리 파이프라인에서 V4-Flash로 전환했을 때 월 $3,000 API 비용이 수십 달러로 줄어드는 시나리오가 현실적이다. 물론 작업 품질 검증이 선행돼야 한다.
V4-Pro는 오픈AI의 12분의 1 수준이지만, 프론티어 모델 성능을 요구하는 에이전틱 작업에서도 경쟁력이 있다고 Lambda AI 벤치마크는 평가했다. 단, 이 벤치마크 수치를 그대로 믿기보다는 자신의 작업 유형으로 직접 테스트하는 것을 권장한다.
2026년 5월 22일, 블룸버그는 딥시크가 약 70억 위안(100억 달러 규모) 투자 유치를 진행 중이라고 보도했다. 딥시크의 첫 외부 자금 유치다. 창업자 량원펑은 투자자 미팅에서 두 가지를 명확히 했다.
첫째, AGI가 1순위 목표다. 단기 상용화나 수익 극대화보다 범용인공지능 달성을 우선하겠다는 뜻이다. "돈보다 AGI"는 오픈AI가 초기에 내세웠던 비영리 사명과 유사한 메시지다. 실제로 이 기조를 유지할지는 시간이 판단할 것이다.
둘째, 오픈소스 유지를 약속했다. 투자 유치 이후에도 모델 가중치를 공개하는 정책을 이어가겠다고 했다. 딥시크는 R1, V3에 이어 V4도 오픈소스로 냈다. 이 패턴이 이번 라운드 이후에도 지속되는지가 개발자 입장에서 핵심 관전 포인트다.
V4의 핵심 구조적 특징은 두 가지다.
MoE(Mixture-of-Experts): 1.6조 파라미터 전체를 항상 활성화하지 않는다. 입력에 따라 적합한 '전문가(expert)' 서브네트워크만 선택해 활성화한다. V4-Pro에서는 49B만 실제로 작동한다. 이 방식은 추론 비용을 낮추면서 전체 파라미터 규모의 표현력을 유지할 수 있게 한다.
하이브리드 어텐션(CSA + HCA): 압축 희소 어텐션(Compressed Sparse Attention)과 강압축 어텐션(Heavily Compressed Attention)을 결합해 긴 컨텍스트 처리 시 메모리 효율을 높였다. 1M 컨텍스트를 지원하면서도 KV 캐시 메모리 부담을 줄이는 방향이다.
공식 Hugging Face 저장소(deepseek-ai/DeepSeek-V4-Pro)에 가중치와 기술 보고서가 공개돼 있다. 아키텍처 세부 사항은 공식 문서에서 직접 확인하는 것을 권장한다.
비용이 저렴하다는 것만으로 선택 근거가 되진 않는다. 판단 체크리스트를 정리했다.
딥시크 V4 공개와 AGI 선언이 개발자에게 의미하는 것은 단순한 가격 인하 이상이다.
공급 다변화 → 협상력 증가: 오픈AI와 앤트로픽 두 곳에 집중됐던 LLM 공급이 딥시크, 미스트랄, 메타 Llama, Qwen으로 분산되고 있다. SiliconANGLE은 이 경쟁이 "다운스트림 개발자의 협상력을 높이고 락인 리스크를 줄인다"고 평가했다.
오픈소스 모델의 현실화: 1년 전까지만 해도 셀프호스팅 오픈소스 LLM은 클로즈드 모델 대비 품질 격차가 뚜렷했다. 지금은 에이전틱 코딩 같은 특정 작업에서 동급 비교가 가능한 수준이 됐다. MIT 라이선스 모델을 운영 인프라에 내장하는 전략이 현실적인 선택지가 됐다.
가격 하락 추세의 가속: 딥시크의 저가 공세에 대응해 오픈AI와 앤트로픽도 소형 모델 가격을 내리는 압력을 받는다. 개발자 입장에서는 전체 LLM 비용 구조가 장기적으로 하락하는 방향으로 가고 있다는 신호다.
오픈소스 AGI 경쟁의 리스크: 딥시크가 AGI를 오픈소스로 추구한다는 선언은 긍정적으로 읽히지만, AI 안전성과 통제 가능성 측면에서 우려도 있다. "위험해서 공개 못한다"는 빅테크의 기조와 정반대 포지션이다. 사용자가 이 판단 근거를 직접 평가해야 한다.