메시지 큐 아키텍처 심층 분석 — Kafka vs RabbitMQ vs Redis Streams, 프로덕션에서 어떤 걸 골라야 하는가
백엔드 시스템이 단일 서버를 넘어서는 순간, 서비스 간 통신 문제가 등장한다. HTTP 동기 호출만으로는 트래픽 급증 시 연쇄 장애가 발생하고, 처리 속도가 다른 서비스 사이에서 데이터가 유실된다. 메시지 큐를 도입하는 이유는 대부분 다음 세 가지 중 하나다: 속도 불일치 해소 : 주문 API는 50ms에 응답해야 하지만, 결제 처리는 3초가 걸린다. 동기 호출이면 사용자는 3초를 기다려야 한다.
백엔드 시스템이 단일 서버를 넘어서는 순간, 서비스 간 통신 문제가 등장한다. HTTP 동기 호출만으로는 트래픽 급증 시 연쇄 장애가 발생하고, 처리 속도가 다른 서비스 사이에서 데이터가 유실된다. 메시지 큐는 이 문제를 비동기 버퍼로 해결하는 인프라다.
Kafka, RabbitMQ, Redis Streams—세 가지 모두 “메시지를 보내고 받는다”는 점은 같지만, 내부 아키텍처와 보장 수준이 근본적으로 다르다. 이 글은 각 시스템의 내부 동작 원리를 분석하고, 프로덕션 워크로드 특성에 따라 어떤 선택이 맞는지 판단 기준을 제시한다.
※ 이 글은 2026년 4월 기준, Apache Kafka 3.9, RabbitMQ 4.1, Redis 7.4 공식 문서를 기반으로 작성됐습니다.
메시지 큐가 해결하는 진짜 문제
메시지 큐를 도입하는 이유는 대부분 다음 세 가지 중 하나다:
속도 불일치 해소: 주문 API는 50ms에 응답해야 하지만, 결제 처리는 3초가 걸린다. 동기 호출이면 사용자는 3초를 기다려야 한다.
부하 평탄화(load leveling): 초당 1만 건의 이벤트가 발생해도, 컨슈머가 초당 1,000건만 처리할 수 있다면 나머지는 큐에 쌓아두고 순서대로 소화한다.
장애 격리: 하류 서비스가 죽어도 메시지는 큐에 남아 있고, 복구 후 이어서 처리할 수 있다.
단순히 “비동기 처리”를 위해 메시지 큐를 도입하는 것이 아니다. 핵심은 서비스 간 결합도를 낮춰서 장애 전파를 차단하는 것이다. 이 관점에서 세 시스템의 아키텍처 차이가 선택을 결정한다.
Apache Kafka — 로그 기반 스트리밍의 핵심 구조
Kafka는 “메시지 큐”라기보다 분산 커밋 로그에 가깝다. 프로듀서가 메시지를 토픽의 파티션에 append-only로 쓰고, 컨수머는 오프셋을 기억하며 순서대로 읽는다. 읽어도 메시지가 삭제되지 않는다는 점이 전통적 메시지 큐와의 근본적 차이다.
핵심 아키텍처 요소:
토픽(Topic): 메시지 카테고리. 내부적으로 N개의 파티션으로 분할된다.
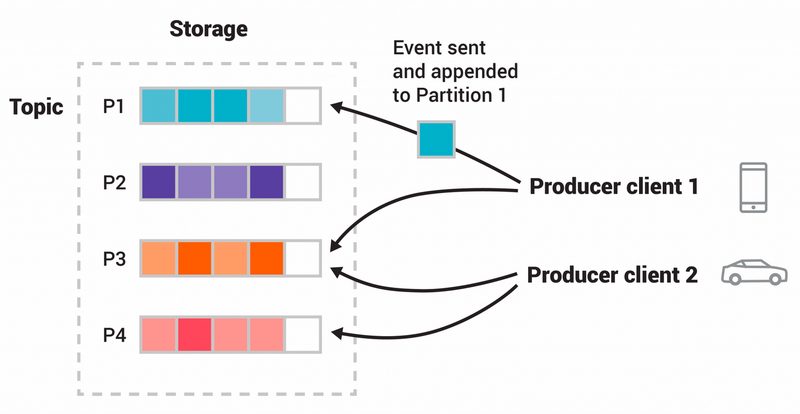
파티션(Partition): 순서 보장의 단위. 같은 파티션 내 메시지는 순서가 보장되지만, 파티션 간에는 보장되지 않는다.
컨슈머 그룹(Consumer Group): 같은 그룹의 컨슈머들은 파티션을 나눠 갖는다. 병렬 처리의 기본 단위.
오프셋(Offset): 컨슈머가 어디까지 읽었는지 추적하는 포인터. 컨슈머가 직접 관리한다.
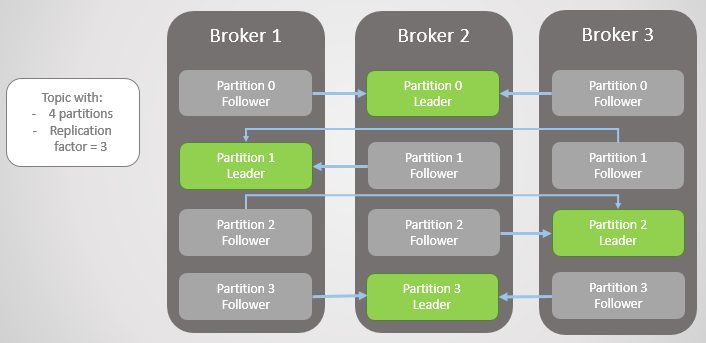
복제(Replication): 각 파티션은 N개 브로커에 복제된다. 리더 브로커가 죽으면 팔로워가 승격한다.
Kafka의 강점은 처리량(throughput)이다. 순차 I/O, 배치 압축, 제로커피 전송으로 단일 파티션에서 초당 수십만 건을 처리한다. LinkedIn의 실제 발표에 따르면 Kafka 클러스터가 하루 7조 건의 메시지를 처리한다(2023년 발표 기준).
반면 단점도 명확하다. 운영 복잡도가 높다. ZooKeeper 또는 KRaft 모드 설정, 파티션 재배치, ISR(In-Sync Replicas) 모니터링 등 운영 할 것이 많다. 또한 메시지 단위 지연(latency)은 RabbitMQ보다 높을 수 있다—배치 처리로 처리량을 높이는 대신 개별 메시지 전달 속도는 희생할 수 있다.
Kafka 파티션 기반 메시지 분배 구조 (출처: Apache Kafka 공식 문서)
RabbitMQ — AMQP 프로토콜과 전통적 메시지 브로커
RabbitMQ는 AMQP 0-9-1 프로토콜을 기반으로 하는 전통적 메시지 브로커다. Kafka와 달리 메시지가 컨슈머에게 전달되면 큐에서 제거되는 “전통적 큐” 동작을 한다.
핵심 아키텍처 요소:
Exchange: 프로듀서가 메시지를 보내는 라우팅 허브. direct, fanout, topic, headers 4가지 타입이 있다.
Queue: 메시지가 실제로 저장되는 버퍼. 컨슈머는 큐를 구독한다.
Binding: Exchange와 Queue를 연결하는 규칙. 라우팅 키로 조건을 설정할 수 있다.
Ack/Nack: 컨수머가 메시지 처리 완료를 명시적으로 응답한다. Nack 시 재큐잉 또는 Dead Letter Queue로 이동.
RabbitMQ의 장점은 유연한 라우팅이다. topic exchange를 쓰면 order.*.created 같은 패턴 매칭으로 메시지를 선택적으로 라우팅할 수 있다. 또한 메시지 단위 지연이 낮다—일반적으로 1ms 이하로 메시지가 컨수머에게 전달된다.
단점은 처리량 한계다. 큐당 초당 수만 건을 처리할 수 있지만, Kafka처럼 초당 수백만 건은 어렵다. 또한 메시지가 소비되면 사라지기 때문에, Kafka처럼 이벤트를 다시 읽거나 재처리하려면 별도의 설계가 필요하다.
Redis Streams는 Redis 5.0에서 도입된 데이터 구조로, Kafka의 로그 기반 모델을 Redis 내부에 구현한 것이다. XADD로 메시지를 추가하고, XREADGROUP으로 컨슈머 그룹 단위로 읽는다.
핵심 특징:
컨슈머 그룹: Kafka와 유사하게 컨슈머 그룹을 지원한다. 각 컨슈머는 자신이 읽은 마지막 ID를 기억한다.
XACK: 메시지 처리 완료를 명시적으로 응답. 응답하지 않으면 PEL(Pending Entries List)에 남아 재처리 가능.
메모리 기반: 디스크가 아닌 메모리에 데이터를 저장한다. MAXLEN으로 스트림 길이를 제한하지 않으면 메모리가 계속 증가한다.
Redis Streams 컨수머 그룹 기본 사용법
# 스트림에 메시지 추가
XADD order-events * action created orderId 12345 region kr
# 컨수머 그룹 생성 및 읽기
XGROUP CREATE order-events payment-service $ MKSTREAM
XREADGROUP GROUP payment-service consumer-1 COUNT 10 BLOCK 5000 STREAMS order-events >
# 처리 완료 응답
XACK order-events payment-service 1712150400000-0
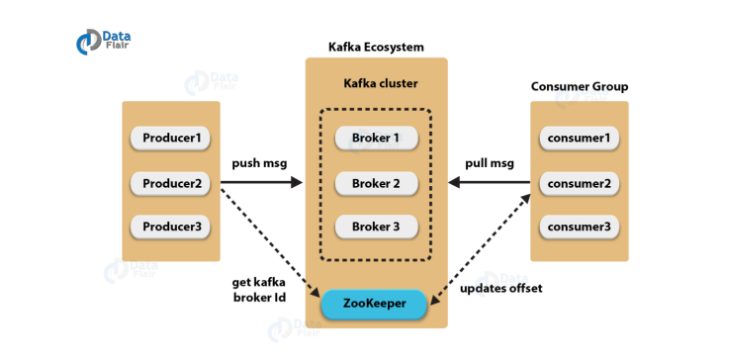
세 메시지 시스템의 내부 동작 방식 비교 (출처: 저자 작성)
Redis Streams의 최대 장점은 도입 비용이 없다는 것이다. 이미 Redis를 쓰고 있다면 별도 인프라 없이 메시지 큐 기능을 쓸 수 있다. 지연도 매우 낮다—서브밀리초 단위.
한계는 내구성(durability)이다. Redis는 기본적으로 메모리 저장이고, AOF/RDB 영속화를 켜도 Kafka나 RabbitMQ의 디스크 기반 보장에 미치지 못한다. 또한 파티션 개념이 없어서 단일 스트림의 처리량은 Redis 서버 하나의 성능에 바인딩된다.
프로덕션 워크로드별 선택 기준
기준
Kafka
RabbitMQ
Redis Streams
처리량
초당 수백만 건
초당 수만 건
초당 수십만 건
지연
5~15ms (배치)
<1ms
서브밀리초
메시지 보존
소비 후에도 유지 (보존 기간 설정)
소비 후 제거
MAXLEN 설정에 따라 다름
순서 보장
파티션 내 보장
큐 내 보장
스트림 내 보장
내구성
디스크 + 복제
디스크 + 미러링/쿼럼
메모리 + AOF(선택)
운영 복잡도
높음
중간
낮음
클라이언트 언어
Java/Kotlin 주력, 다언어 지원
전 언어 지원
Redis 클라이언트 있는 모든 언어
이 표만으로는 선택이 어렵다. 실제 판단 기준은 워크로드 특성이다:
Kafka를 선택해야 할 때: 이벤트 스트리밍이 핵심인 시스템. 발생한 이벤트를 여러 컨슈머가 각자의 속도로 읽어야 하는 경우. 로그 집계, CDC(Change Data Capture), 실시간 데이터 파이프라인.
RabbitMQ를 선택해야 할 때: 작업 큐(task queue) 패턴. 메시지가 정확히 한 번만 처리되어야 하고, 복잡한 라우팅이 필요한 경우. 주문 처리, 이메일 발송, 백그라운드 작업 분배.
Redis Streams를 선택해야 할 때: 이미 Redis를 사용 중이고, 메시지 유실이 치명적이지 않은 경우. 실시간 알림, 세션 이벤트, 가벼운 작업 큐.
운영 복잡도와 장애 대응 차이
선택 시 가장 간과하기 쉬운 부분이 운영 복잡도다. 벤치마크 수치만 보고 Kafka를 도입했다가 운영에서 무너지는 팀이 많다.
Kafka 운영 체크리스트:
KRaft 모드 또는 ZooKeeper 클러스터 관리 (최소 3노드)
파티션 수 계획—한 번 만들면 줄일 수 없고, 늘리면 리밸런싱 필요
ISR(In-Sync Replicas) 모니터링—ISR이 줄어들면 가용성 vs 일관성 트레이드오프 결정 필요
컨슈머 래그(lag) 모니터링—래그가 계속 늘면 컨수머 스케일 아웃 필요
로그 보존 정책—디스크 용량 계획 필수
RabbitMQ 운영 체크리스트:
클러스터링 설정 (미러링 또는 쿼럼)
Memory/Disk 알람 임계값 설정
Dead Letter Queue 구성—실패한 메시지 처리 전략
Prefetch count 튜닝—너무 높으면 메모리 폭발, 너무 낮으면 처리량 저하
Redis Streams 운영 체크리스트:
MAXLEN 설정으로 메모리 관리
PEL(Pending Entries List) 모니터링—처리 안 된 메시지 추적
AOF 영속화 설정 (필요시)
프로덕션 장애 시나리오 • Kafka 브로커 1대 다운 → ISR이 충분하면 자동 리더 승격, 컨슈머 리밸런싱 발생할 수 있음 • RabbitMQ 노드 1대 다운 → 미러링 설정 시 자동 전환, 단 전환 중 미응답 메시지 재전송 필요 • Redis 장애 → AOF 없으면 메모리의 모든 데이터 유실. Sentinel/Cluster 설정 필수
운영 복잡도와 처리량의 트레이드오프 (출처: 저자 작성)
흔한 실수와 안티패턴
메시지 큐를 도입한 후 가장 많이 발생하는 실수들을 정리한다.
1. 메시지 큐를 데이터베이스로 쓰는 것
메시지에 모든 데이터를 넣으면 메시지 크기가 커지고 처리량이 급감한다. 메시지에는 이벤트 타입 + 식별자(ID)만 넣고, 실제 데이터는 컨수머가 DB에서 직접 조회하는 것이 일반적이다.
2. 멱등성 처리(idempotency)를 무시하는 것
메시지 큐는 "at-least-once" 전달을 기본으로 한다. 컨수머 장애 후 재시작하면 같은 메시지를 두 번 받을 수 있다. 결제 처리, 재고 차감 같은 작업은 반드시 멱등성 키(idempotency key)로 중복 실행을 방지해야 한다.
3. Dead Letter Queue 없이 운영하는 것
처리 실패한 메시지가 무한 재시도되면 컨수머 리소스를 잠식한다. 일정 횟수 실패 후 Dead Letter Queue로 이동시켜서 별도 처리하는 전략이 필수다.
4. 컨수머 처리 순서에 의존하는 설계
Kafka는 파티션 내에서만 순서를 보장한다. 전체 순서가 중요한 워크로드라면 파티션 키 설계를 신중하게 해야 한다. 주문 ID를 파티션 키로 쓰면 같은 주문의 이벤트는 같은 파티션에 모여 순서가 보장된다.
실제 아키텍처 예시 — 주문 처리 시스템
주문 처리 시스템을 예로 각 시스템으로 구현할 때의 차이를 정리한다.
Kafka 기반: 주문 생성 → order-events 토픽에 발행 → 결제 서비스·재고 서비스·알림 서비스가 각자의 컨슈머 그룹으로 독립적으로 읽는다. 한 번 발행된 이벤트를 여러 서비스가 각자의 속도로 소비할 수 있다.
RabbitMQ 기반: 주문 생성 → order-exchange(fanout)로 발행 → 결제 큐·재고 큐·알림 큐에 각각 복사된다. 각 큐는 전담 컨수머가 처리하고, 처리된 메시지는 사라진다. 실패 시 Dead Letter Queue로 이동.
Redis Streams 기반: 주문 생성 → XADD order-events → 결제·재고·알림 각각 별도 컨슈머 그룹으로 읽는다. Kafka와 유사하지만 단일 서버 성능에 바인딩된다.