LLM 앱을 프로덕션에 배포하기 시작한 팀들이 공통으로 겪는 문제가 있다. 프롬프트를 조금 바꿨더니 다른 기능이 망가졌고, 새 모델 버전으로 교체했더니 출력 품질이 눈에 띄게 달라졌다. 일반 소프트웨어 테스트는 결정론적이다. 함수에 입력을 넣으면 항상 같은 출력이 나오고, assert output == expected 로 검증할 수 있다.
LLM 앱을 프로덕션에 배포하기 시작한 팀들이 공통으로 겪는 문제가 있다. 프롬프트를 조금 바꿨더니 다른 기능이 망가졌고, 새 모델 버전으로 교체했더니 출력 품질이 눈에 띄게 달라졌다. 그런데 무엇이 얼마나 달라졌는지 측정할 방법이 없다. LLM Evals(평가 파이프라인)는 이 문제를 해결한다. AI 앱의 출력 품질을 정량 지표로 측정하고, CI/CD에 품질 게이트를 붙여 배포 전에 회귀를 잡아내는 실무 가이드를 정리한다.
AI 서비스를 프로덕션에 운영 중이거나, LLM 기반 기능에 테스트를 붙이고 싶은 백엔드/풀스택 개발자에게 필요한 글이다.
LLM 평가 파이프라인 — 개발 단계 evals와 프로덕션 모니터링의 구조
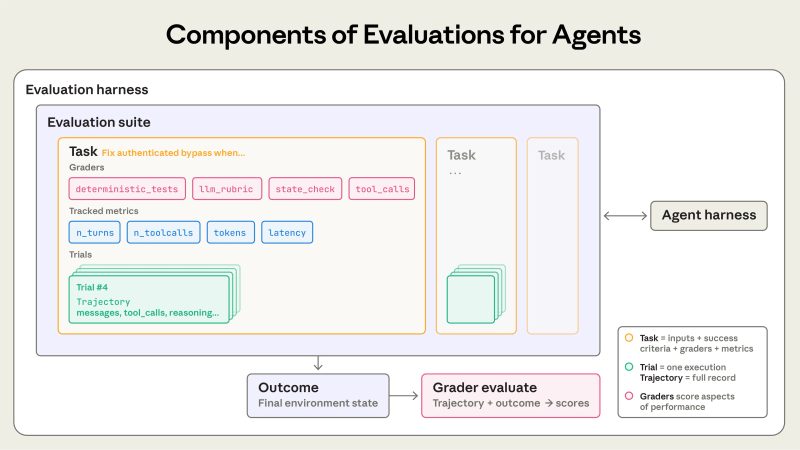
LLM Evals란 무엇인가 — 단순 assert와 다른 이유
일반 소프트웨어 테스트는 결정론적이다. 함수에 입력을 넣으면 항상 같은 출력이 나오고, assert output == expected로 검증할 수 있다. LLM은 다르다. 같은 프롬프트에도 출력이 매번 달라지고, '정답'이 하나가 아닌 경우가 많다.
LLM Evals는 이 비결정론적 출력을 다음 세 가지 축으로 평가한다.
관련성(Relevance): 답변이 질문에 실제로 응답하는가
충실도(Faithfulness): RAG 시스템이라면 컨텍스트 문서의 내용과 일치하는가
할루시네이션(Hallucination): 근거 없는 사실을 만들어냈는가
이 지표들은 단순 문자열 비교로는 측정할 수 없다. 그래서 세 가지 측정 방식이 쓰인다.
LLM-as-Judge: GPT-4나 Claude를 심판으로 써서 출력 품질을 자동 채점
휴리스틱 지표: BLEU, ROUGE 같은 텍스트 유사도 점수 (빠르지만 의미 파악 못함)
임베딩 유사도: 기대 답변과 실제 출력의 의미적 거리를 벡터로 측정
핵심 Evals 도구 3종 비교 — DeepEval, Langfuse, Braintrust
2026년 현재 가장 많이 쓰이는 LLM 평가 도구는 세 가지로 정리된다. 포지션이 다르기 때문에 보통 두 가지를 조합해서 쓴다.
소규모 팀이라면 DeepEval + Langfuse 조합이 현실적이다. DeepEval로 CI 테스트를 붙이고, Langfuse로 프로덕션 트레이스를 수집해 품질 추세를 모니터링한다. Braintrust는 프롬프트 실험이 잦은 팀에 더 적합하다.
LLM-as-Judge는 GPT-4나 Claude 같은 강력한 모델을 심판으로 써서 평가 대상 모델의 출력을 자동으로 채점하는 패턴이다. 사람이 직접 평가하는 Human Evaluation보다 빠르고, 단순 휴리스틱보다 의미를 더 잘 이해한다.
핵심은 루브릭(채점 기준) 설계다. 심판 모델에게 모호한 지시를 주면 채점 일관성이 떨어진다. 잘 설계된 루브릭은 다음 요소를 포함한다.
0~5점 척도 정의: 각 점수가 무엇을 의미하는지 구체적으로 명시
평가 차원 분리: 관련성, 완성도, 정확성을 각각 따로 채점
근거 요청: 심판 모델이 점수와 함께 이유를 설명하도록 강제 (CoT)
형식 고정: JSON 출력 강제로 파싱 오류 방지
LLM-as-Judge 루브릭 프롬프트 예시 (Python)
from openai import OpenAI
import json
client = OpenAI()
def judge_response(question: str, answer: str, context: str) -> dict:
prompt = f"""
You are an expert evaluator for AI assistant responses.
Evaluate the following response on two dimensions.
Question: {question}
Context: {context}
Answer: {answer}
Return JSON with this exact format:
{{
"relevance": {{"score": 0-5, "reason": "..."}},
"faithfulness": {{"score": 0-5, "reason": "..."}}
}}
Scoring guide:
- relevance 5: Directly and completely answers the question
- relevance 3: Partially answers, some irrelevant content
- relevance 0: Does not address the question at all
- faithfulness 5: All claims are supported by the context
- faithfulness 0: Contains claims not in the context (hallucination)
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
주의: LLM-as-Judge는 심판 모델에도 편향이 있다. GPT-4는 GPT 계열 출력을 약간 편호하고, Claude는 긴 답변에 더 높은 점수를 주는 경향이 있다. 같은 평가 세트를 여러 심판 모델로 돌려보거나, 주기적으로 Human Evaluation으로 심판 모델 자체의 정확도를 교차 검증하는 것이 좋다.
CI/CD 통합 실전 — PR마다 품질 게이트 붙이기
DeepEval을 GitHub Actions에 통합하면 PR이 열릴 때마다 LLM 출력 품질을 자동 검사하고, 점수가 임계값 아래로 떨어지면 merge를 차단할 수 있다.
DeepEval 유닛 테스트 예시 (Python)
# tests/test_rag_quality.py
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric, FaithfulnessMetric
from deepeval.test_case import LLMTestCase
from my_rag_app import query_rag
def test_rag_answer_quality():
# 실제 앱 함수를 호출해 테스트 케이스 생성
question = "What is the capital of France?"
result = query_rag(question)
test_case = LLMTestCase(
input=question,
actual_output=result["answer"],
retrieval_context=result["source_docs"]
)
assert_test(test_case, metrics=[
AnswerRelevancyMetric(threshold=0.7),
FaithfulnessMetric(threshold=0.8)
])