GraphRAG — 지식 그래프 기반 RAG가 벡터 검색을 이기는 조건과 프로덕션 도입 가이드
한 줄 요약: GraphRAG는 문서에서 지식 그래프를 자동 추출한 뒤 그래프 구조를 활용해 검색하는 방식이다. 단순 벡터 RAG 대비 멀티홉 질의 정확도 2배, 요약 정확도 1.5배 를 달성하며, LazyGraphRAG로 인덱싱 비용이 99.9% 감소해 프로덕션 도입 장벽이 사라졌다. 대부분의 RAG 시스템은 동일한 구조를 따른다. 문서를 청크로 나누고, 임베딩 벡터로 변환한 뒤, 사용자 질의와 코사인 유사도가 높은 청크를 LLM 컨텍스트에 넣는다.
한 줄 요약: GraphRAG는 문서에서 지식 그래프를 자동 추출한 뒤 그래프 구조를 활용해 검색하는 방식이다. 단순 벡터 RAG 대비 멀티홉 질의 정확도 2배, 요약 정확도 1.5배를 달성하며, LazyGraphRAG로 인덱싱 비용이 99.9% 감소해 프로덕션 도입 장벽이 사라졌다.
벡터 검색 기반 RAG가 단순 키워드 매칭 수준에서 벗어나지 못하는 한계를 느꼈다면, 이 글이 다음 단계를 판단하는 데 도움이 된다. Microsoft Research가 오픈소스로 공개한 GraphRAG의 2단계 파이프라인(엔티티 추출 → 커뮤니티 요약), 벤치마크 비교, LazyGraphRAG의 비용 혁신, 그리고 프로덕션 적용 시 고려해야 할 트레이드오프를 정리한다.
※ 이 글은 2026년 4월 기준, Microsoft GraphRAG 공식 문서와 arxiv 논문(2502.11371), 실무 사례 데이터를 참조하여 작성됐습니다.
벡터 RAG는 왜 한계에 부딪히는가
대부분의 RAG 시스템은 동일한 구조를 따른다. 문서를 청크로 나누고, 임베딩 벡터로 변환한 뒤, 사용자 질의와 코사인 유사도가 높은 청크를 LLM 컨텍스트에 넣는다. 이 방식은 단일 문서 안에서 답이 완결되는 질문에는 잘 작동한다.
문제는 실무에서 흔한 질문들이 이 범주를 벗어난다는 것이다. "지난 분기 가장 많이 언급된 기술 리스크 3가지는?" 같은 질의는 수십 개 문서에 흩어진 정보를 종합해야 한다. 벡터 검색은 개별 청크의 유사도만 볼 뿐, 문서 간 관계나 전체 맥락을 이해하지 못한다.
arxiv 논문(RAG vs. GraphRAG: A Systematic Evaluation, 2025)의 벤치마크 결과가 이 한계를 수치로 보여준다.
질의 유형
벡터 RAG 정확도
GraphRAG 정확도
차이
단일홉 질문
72%
68%
벡터 RAG +4%
멀티홉 질문
41%
80%
GraphRAG +39%
전체 요약
51%
90%
GraphRAG +39%
출처: arxiv 2502.11371 — RAG vs. GraphRAG: A Systematic Evaluation and Key Insights
멀티홉·요약 질의에서 GraphRAG가 벡터 RAG를 크게 앞선다 (출처: arxiv 2502.11371 재구성)
GraphRAG는 어떻게 작동하는가 — 2단계 파이프라인
Microsoft Research가 2024년에 공개하고 오픈소스(MIT 라이선스)로 배포한 GraphRAG의 핵심은 인덱싱 단계에서 지식 그래프를 자동 구축하는 것이다. 전체 파이프라인은 두 단계로 나뉜다.
1단계: 엔티티·관계 추출 (Entity & Relationship Extraction)
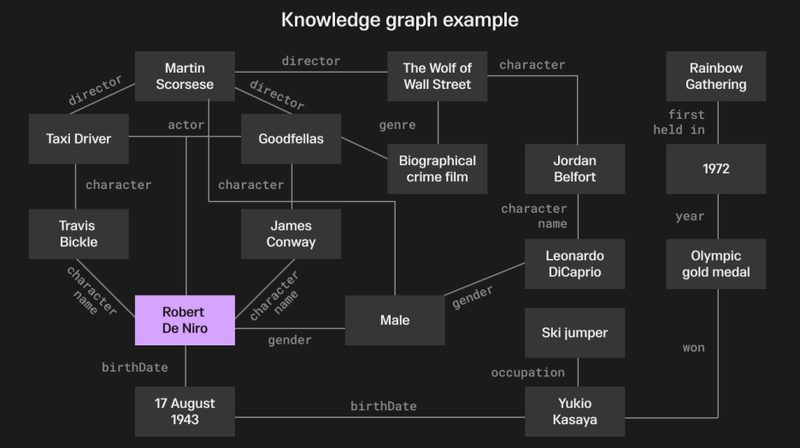
LLM이 문서 청크를 읽고 엔티티(인물, 조직, 기술, 개념)와 엔티티 간 관계를 추출한다. 예를 들어 "Anthropic이 Claude Opus 4.6을 출시했다"에서 Anthropic → 출시 → Claude Opus 4.6 관계가 추출된다. 이 과정에서 동일 엔티티의 다른 표현("Anthropic", "앤트로픽", "Anthropic Inc.")도 하나로 통합된다.
2단계: 커뮤니티 탐지 & 요약 (Community Detection & Summarization)
추출된 그래프에 Leiden 알고리즘을 적용해 밀접하게 연결된 엔티티 그룹(커뮤니티)을 자동으로 묶는다. 각 커뮤니티에 대해 LLM이 요약문을 생성한다. 이 커뮤니티 요약이 GraphRAG의 핵심 자산이다. 사용자 질의가 들어오면, 관련 커뮤니티 요약을 검색해 LLM에 전달한다.
GraphRAG 설치 및 빠른 시작 (Python)
# 설치
pip install graphrag
# 프로젝트 초기화
graphrag init --root ./my-project
# input/ 폴더에 텍스트 파일 배치 후 인덱싱
graphrag index --root ./my-project
# 글로벌 질의 (커뮤니티 요약 기반)
graphrag query --root ./my-project \
--method global \
--query "이 문서 전체에서 가장 중요한 기술 트렌드 3가지는?"
# 로컬 질의 (엔티티 그래프 탐색 기반)
graphrag query --root ./my-project \
--method local \
--query "GraphRAG와 벡터 RAG의 차이점은?"
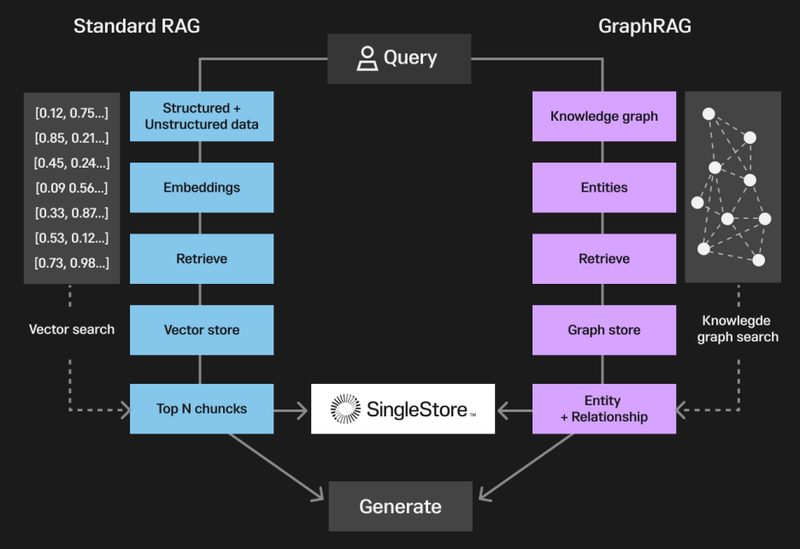
핵심 차이는 질의 모드에 있다. Global 질의는 커뮤니티 요약을 map-reduce 방식으로 종합해 전체 문서에 대한 요약형 답변을 생성한다. Local 질의는 관련 엔티티에서 시작해 그래프를 탐색하며 연결된 정보를 수집한다. 벡터 RAG에서는 불가능한 "문서 전체를 아우르는 답변"이 Global 질의로 가능해진다.
GraphRAG 인덱싱-질의 파이프라인 구조 (출처: Microsoft Research 공식 블로그)
LazyGraphRAG가 바꾼 비용 구조 — 인덱싱 비용 99.9% 감소
GraphRAG의 가장 큰 진입 장벽은 인덱싱 비용이었다. 원본 GraphRAG로 대규모 문서(수만 페이지)를 인덱싱하면 LLM 호출이 수천 번 발생하고, 비용이 $20,000~$33,000에 달하는 사례가 보고됐다. 이 때문에 "학술적으로는 인상적이지만 프로덕션에서는 쓸 수 없다"는 평가가 지배적이었다.
2025년 6월, Microsoft Research가 공개한 LazyGraphRAG가 이 문제를 해결했다. LazyGraphRAG의 핵심 아이디어는 단순하다: 그래프 구축을 쿼리 시점까지 지연(lazy)시키는 것이다.
기존 GraphRAG는 모든 문서에 대해 사전에 엔티티 추출과 커뮤니티 요약을 수행한다. LazyGraphRAG는 인덱싱 시점에 NLP 기반 경량 엔티티 추출(NER)만 수행하고, LLM 호출 없이 키워드 그래프를 구축한다. 실제 LLM 기반 분석은 사용자 질의가 들어올 때 관련 부분에 대해서만 실행된다.
항목
GraphRAG (Full)
LazyGraphRAG
인덱싱 비용 (10만 페이지)
$20,000~$33,000
$2~$5
인덱싱 시간
수 시간~수일
수 분
쿼리 시 LLM 호출
최소 (사전 요약 활용)
쿼리별 관련 부분만
Global 질의 품질
최고
동등 (96% 승률 vs 벡터 RAG)
출처: Microsoft Research LazyGraphRAG 기술 블로그 (2025.06)
GraphRAG를 써야 할 때와 쓰지 말아야 할 때
GraphRAG가 벡터 RAG보다 항상 우월한 것은 아니다. 2026년 2월 발표된 독립 평가 프레임워크(arxiv 2506.06331)는 "기존 GraphRAG 논문들의 성능 개선이 평가 편향에 의해 과대 보고됐을 수 있다"고 지적했다. 실무에서의 판단 기준은 다음과 같다.
GraphRAG가 적합한 경우:
법률 문서, 기술 보고서, 연구 논문 등 정적이고 고가치인 문서 집합
"전체 문서에서 가장 많이 언급된 리스크는?" 같은 멀티홉·요약형 질의가 주요 사용 패턴
엔티티 간 관계 파악이 핵심인 도메인 (제약·금융·법률)
문서가 자주 변경되지 않는 환경 (월 1회 이하 업데이트)
벡터 RAG가 여전히 나은 경우:
실시간으로 문서가 추가·수정되는 환경 (채팅 로그, 티켓 시스템)
"이 API의 파라미터는?" 같은 단일 문서 안에서 완결되는 질의
인덱싱 비용과 지연 시간이 크리티컬한 경우
문서 수가 수백 건 이하로 적은 경우
질의 유형과 문서 특성에 따른 RAG 아키텍처 선택 가이드 (출처: 자체 구성)
프로덕션 도입 시 알아야 할 5가지
GraphRAG를 실제 서비스에 적용하려면 문서만으로는 알기 어려운 실무 포인트가 있다. 2026년 현재 프로덕션에서 GraphRAG를 운영 중인 팀들의 사례를 종합하면 다음 5가지가 핵심이다.
1. LLM 선택이 인덱싱 품질을 결정한다 엔티티 추출에 사용하는 LLM의 품질이 곧 그래프 품질이다. GPT-4o 이상을 권장하며, GPT-4o Mini나 소형 모델을 쓰면 엔티티 누락률이 30% 이상 증가한다는 보고가 있다. 비용과 품질의 트레이드오프를 테스트해야 한다.
2. 청킹 전략이 다르다 벡터 RAG에서는 512~1024 토큰 단위로 청킹하는 것이 일반적이다. GraphRAG에서는 의미 단위 청킹(semantic chunking)이 더 효과적이다. 문단이나 섹션 단위로 나눠야 엔티티 간 관계가 하나의 청크 안에 보존된다.
3. 그래프 DB는 필수가 아니다 Neo4j 같은 그래프 DB를 반드시 써야 한다고 생각하기 쉽지만, Microsoft GraphRAG 기본 구현은 Parquet 파일 기반이다. 중소 규모(문서 1만 건 이하)에서는 이 기본 구현으로 충분하며, 그래프 DB는 실시간 탐색이 필요한 대규모 환경에서만 도입을 검토하면 된다.
4. 하이브리드 구조가 현실적이다 실무에서 가장 많이 채택되는 아키텍처는 벡터 RAG + GraphRAG 하이브리드다. 단순 질의는 벡터 검색으로 빠르게 처리하고, 멀티홉·요약 질의만 GraphRAG로 라우팅한다. 질의 분류기를 하나 두는 것만으로 비용 대비 정확도를 극대화할 수 있다.
5. 평균 지연 시간 2.4배 증가를 감수해야 한다 GraphRAG는 그래프 탐색 + 커뮤니티 요약 조회 과정이 추가되므로 벡터 RAG 대비 평균 2.4배의 지연이 발생한다. 실시간 채팅 인터페이스에서는 체감되는 수준이다. 캐싱 레이어와 비동기 처리를 함께 설계해야 한다.
누가 지금 도입을 검토해야 하는가
지금 당장 검토해야 할 팀:
이미 벡터 RAG 기반 시스템을 운영 중이고, "전체 요약" 또는 "비교 분석" 질의에서 품질 불만이 반복되는 경우
법률·금융·제약 도메인에서 규정 문서 수천 건을 다루는 경우
내부 지식 베이스(Confluence, Notion, SharePoint)에 대한 멀티홉 Q&A를 구축하려는 경우
아직 시기상조인 팀:
RAG 자체를 처음 도입하는 단계라면, 먼저 벡터 RAG로 기본기를 잡는 것이 우선이다
문서가 실시간으로 변경되는 환경(채팅 로그, 실시간 이슈 트래커)에서는 인덱싱 재구축 비용이 문제가 된다
문서 수가 수백 건 이하라면, 벡터 RAG와 GraphRAG의 품질 차이가 크지 않을 수 있다
GraphRAGRAG지식 그래프Knowledge Graph벡터 검색LLMMicrosoftLazyGraphRAG엔터프라이즈 AI검색 증강 생성