Google Gemma 4 — Apache 2.0으로 전환된 오픈소스 LLM, 실무 도입 가이드
2026년 4월 2일, Google DeepMind가 Gemma 4를 Apache 2.0 라이선스 로 공개했다. 이전 Gemma 시리즈의 Google 커스텀 라이선스가 만들어온 법적 불확실성이 사라졌다. Gemma 1, 2, 3은 Google의 커스텀 라이선스를 사용했다. 이 라이선스는 겉보기에 오픈소스처럼 보였지만, 실제로는 몇 가지 중요한 제약이 있었다.
2026년 4월 2일, Google DeepMind가 Gemma 4를 Apache 2.0 라이선스로 공개했다. 이전 Gemma 시리즈의 Google 커스텀 라이선스가 만들어온 법적 불확실성이 사라졌다. 상업적 사용, 파인튜닝 후 재배포, 온프레미스 배포 — 모두 허용된다.
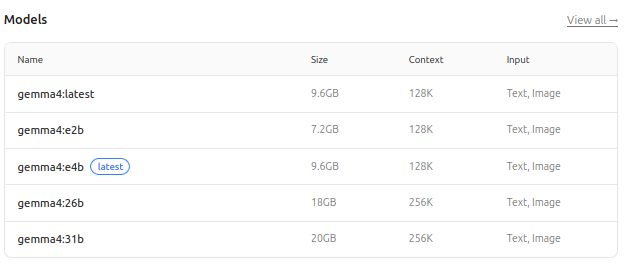
모델은 4종이다: E2B(2.3B), E4B(4.5B), 26B MoE(활성 파라미터 4B), 27B dense. 에지 디바이스부터 클라우드까지 전 환경을 커버하고, Hugging Face와 Google Cloud Vertex AI에서 즉시 사용 가능하다.
대상: 로컬 LLM 운영 또는 파인튜닝을 검토 중인 개발자 · 라이선스 없이 셀프호스트 AI를 도입하려는 팀 · GPT/Claude API 비용 최적화를 고민하는 서비스 개발자
Apache 2.0 전환이 실무에서 의미하는 것
Gemma 1, 2, 3은 Google의 커스텀 라이선스를 사용했다. 이 라이선스는 겉보기에 오픈소스처럼 보였지만, 실제로는 몇 가지 중요한 제약이 있었다.
상업적 재배포 제한: 파인튜닝 결과물을 외부에 서비스 형태로 팔거나 배포할 때 Google의 별도 허가가 필요할 수 있다는 해석 여지가 있었다
법인 규모 제한: 일부 버전에서 연 매출 $50M 이상 기업에 추가 조건이 붙는 조항이 있었다
파생 모델 배포: 파인튜닝한 모델 가중치를 공개 배포하는 경우 라이선스 명시 의무와 조건 계승 여부가 불명확했다
Apache 2.0으로 전환되면서 이 모호함이 전부 사라졌다. 특허 사용 허가, 상업적 사용, 수정, 재배포, 파생물 배포 — 모두 명시적으로 허용되고 법적 해석 여지가 없다.
엔터프라이즈 법무팀이 "이 모델 써도 되나요?"라고 물어봤을 때 Apache 2.0이라면 대답은 단순하다. 이전 Gemma 라이선스라면 몇 주씩 검토가 걸렸다.
Gemma 4 라인업: 에지 디바이스용 2.3B부터 서버 추론 최적화 MoE 26B까지
모델 4종 라인업과 선택 기준
Gemma 4는 용도에 따라 4개 모델로 나뉜다. 각 모델의 실제 사용 시나리오와 함께 정리한다.
주목할 모델은 26B MoE다. MoE(Mixture of Experts) 구조는 추론 시 전체 26B 파라미터를 활성화하지 않고 약 4B만 사용한다. 즉, 26B 규모의 지식을 가지면서 실제 추론 비용은 4B 수준으로 유지할 수 있다.
실용적인 결과는 이렇다: A100 80GB GPU 한 장으로 26B MoE를 서빙할 수 있다. 동급 27B dense 모델이라면 멀티GPU 또는 더 비싼 H100이 필요한 경우가 많다. 비용 민감한 서비스에서 실질적인 대안이 된다.
E2B와 E4B는 로컬 기기 추론에 초점을 맞췄다. Apple Silicon MacBook Pro에서 Ollama 또는 LM Studio로 구동 가능한 수준이다. 완전히 오프라인 환경에서 AI 기능을 제공해야 하는 케이스 — 보안 규정이 엄격한 금융·의료 분야 애플리케이션 — 에 적합하다.
빠른 시작 — Ollama와 Hugging Face 기준
두 가지 경로로 즉시 사용 가능하다.
Ollama로 Gemma 4 로컬 실행
# E4B 모델 다운로드 및 실행
ollama run gemma4:4b
# 26B MoE 모델 (고성능 서버 권장)
ollama run gemma4:26b
# OpenAI 호환 API 서버로 노출
ollama serve
# → http://localhost:11434/v1 (OpenAI API 형식)
Google Cloud Vertex AI를 사용하는 경우 Model Garden에서 Gemma 4 전 모델을 원클릭으로 배포할 수 있다. 파인튜닝도 Vertex AI Supervised Fine-tuning으로 콘솔에서 설정 가능하다.
주의할 점은 채팅 템플릿이다. Gemma 4는 Gemma 2·3과 동일한 <start_of_turn> / <end_of_turn> 포맷을 사용한다. tokenizer.apply_chat_template()을 쓰면 자동으로 처리되지만, 직접 프롬프트를 구성할 경우 포맷이 맞지 않으면 성능이 크게 떨어진다.
Hugging Face의 google/gemma-4 레포지토리에서 전 모델 직접 다운로드 가능
파인튜닝 — 언제 해야 하고 어떻게 시작하나
Apache 2.0 라이선스의 핵심 실익은 파인튜닝 후 재배포다. 파인튜닝한 Gemma 4 가중치를 Hugging Face에 공개하거나, 사내 서비스에 포함시키거나, SaaS 제품에 임베딩해도 법적 제약이 없다.
실무에서 파인튜닝이 필요한 경우:
도메인 특화 용어: 의료·법무·금융·제조 분야처럼 일반 LLM이 다루지 않는 전문 용어가 많을 때
응답 포맷 일관성: JSON 출력, 특정 보고서 형식, 사내 문서 스타일로 항상 응답하도록 할 때
저레이턴시 요구: 프롬프트 엔지니어링으로 해결하면 컨텍스트가 너무 길어지는 케이스
최소 권장 파인튜닝 환경은 E4B 기준 A10G 24GB GPU 1장이다. LoRA/QLoRA를 쓰면 더 낮은 VRAM에서도 가능하다. 26B MoE 파인튜닝은 A100 40GB 이상 권장한다.
TRL + LoRA로 Gemma 4 E4B 파인튜닝 시작 (최소 예시)
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "google/gemma-4-e4b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# LoRA 설정
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# SFT 학습
training_args = SFTConfig(
output_dir="./gemma4-finetuned",
num_train_epochs=3,
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
bf16=True,
learning_rate=2e-4,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=your_dataset, # datasets.Dataset 형식
tokenizer=tokenizer,
)
trainer.train()
Gemma 4 파인튜닝 시 주의사항 • 채팅 템플릿 포맷(<start_of_turn>user\n...<end_of_turn>)을 학습 데이터에도 동일하게 적용할 것 • MoE 모델(26B)은 expert routing 레이어 파인튜닝에 주의 — 일반적으로 attention 레이어만 LoRA 적용 권장 • 파인튜닝 결과물 배포 시 LICENSE에 Apache 2.0 원본 명시 필수 (attribution 조건)
Gemma 4 vs 경쟁 오픈소스 모델 — 어디에 쓰면 유리한가
Apache 2.0 오픈소스 LLM 시장에는 이미 강력한 경쟁자들이 있다. 주요 대안과 비교해 Gemma 4가 유리한 포지션을 정리한다.
Gemma 4가 명확히 유리한 케이스는 세 가지다.
Google Cloud 스택 사용 팀: Vertex AI Model Garden 원클릭 배포, Cloud Run 통합, Google의 지속적 업데이트 보장
에지/온디바이스 AI: E2B(2.3B)·E4B(4.5B)의 경량 모델이 에지 추론에 최적화되어 있고, Llama 4나 Mistral 계열보다 작은 크기 옵션이 더 다양함
엔터프라이즈 법무 리스크 제로: Llama 커스텀 라이선스의 규모 제한 조항 없이 Apache 2.0 단일 라이선스
Apache 2.0 오픈소스 LLM 3파전: 각 모델의 포지셔닝 비교
Gemma 3에서 Gemma 4로 마이그레이션 체크리스트
현재 Gemma 3를 사용 중인 경우, Gemma 4로 전환 시 확인할 사항들이다.
Gemma 4Google DeepMindApache 2.0오픈소스 LLM셀프호스팅Ollama파인튜닝LoRAMoE온프레미스 AI