데이터 엔지니어링 입문 가이드 — ETL/ELT, Apache Airflow, dbt, 웨어하우스 비교
데이터 엔지니어링은 '데이터를 분석 가능한 상태로 만드는 기술'이다. 데이터 사이언티스트가 모델을 학습시키기 전에, 데이터 엔지니어가 데이터를 수집·변환·적재하는 파이프라인을 구축해야 한다. 백엔드 엔지니어는 사용자 요청을 실시간으로 처리하는 OLTP(Online Transaction Processing) 시스템을 만든다.
데이터 엔지니어링은 '데이터를 분석 가능한 상태로 만드는 기술'이다. 데이터 사이언티스트가 모델을 학습시키기 전에, 데이터 엔지니어가 데이터를 수집·변환·적재하는 파이프라인을 구축해야 한다. 이 글은 ETL/ELT 패턴, Apache Airflow 워크플로우, dbt를 활용한 데이터 변환, 데이터 웨어하우스 선택까지 데이터 엔지니어링의 핵심 개념과 실전 도구를 정리한다.
데이터 엔지니어링이란 — 백엔드와 무엇이 다른가
백엔드 엔지니어는 사용자 요청을 실시간으로 처리하는 OLTP(Online Transaction Processing) 시스템을 만든다. 데이터 엔지니어는 이 OLTP 시스템에서 발생한 데이터를 분석과 의사결정에 사용할 수 있는 형태로 변환하는 OLAP(Online Analytical Processing) 시스템을 구축한다.
데이터 엔지니어의 핵심 업무:
데이터 파이프라인 설계: 원천 데이터 → 변환 → 웨어하우스/레이크 적재
데이터 품질 보장: 스키마 검증, 중복 제거, NULL 처리, 데이터 정합성 테스트
파이프라인 오케스트레이션: 스케줄링, 의존성 관리, 실패 시 재시도·알림
데이터 모델링: 분석 쿼리에 최적화된 차원 모델(Star Schema, Snowflake Schema) 설계
데이터 엔지니어 시장 현황: 한국에서 데이터 엔지니어 채용은 2024년 대비 35% 증가했다(원티드 기준). 특히 금융, 이커머스, 게임 업종에서 수요가 높다. 백엔드 엔지니어 대비 공급이 적어, 3년차 기준 연봉이 평균 10~15% 높다. 백엔드에서 데이터 엔지니어링으로 전환하는 개발자가 늘고 있으며, SQL 숙련도와 분산 시스템 이해가 전환의 핵심 역량이다.
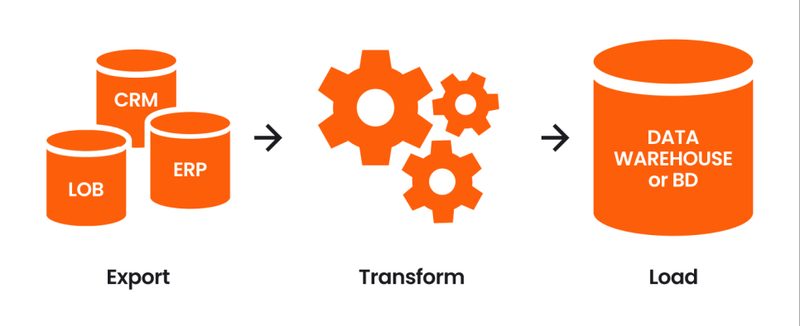
데이터 엔지니어링 파이프라인 전체 구조 — 수집에서 분석까지
ETL vs ELT — 어느 패턴이 맞는가
ETL (Extract → Transform → Load): 데이터를 추출한 뒤, 중간 서버에서 변환하고, 변환된 결과만 웨어하우스에 적재한다. 전통적인 패턴으로, 스토리지 비용이 비싸던 시절에 주로 사용됐다.
ELT (Extract → Load → Transform): 원본 데이터를 웨어하우스에 먼저 적재한 뒤, 웨어하우스 내부에서 변환한다. BigQuery, Snowflake 같은 클라우드 웨어하우스의 컴퓨팅 파워가 충분해지면서 2020년대 이후 주류가 됐다.
비교 항목
ETL
ELT
변환 위치
중간 서버 (Spark, Python)
웨어하우스 내부 (SQL)
스토리지 비용
적음 (변환 후 적재)
많음 (원본 전체 적재)
유연성
낮음 (변환 로직 변경 시 재적재)
높음 (원본 보존, 변환만 수정)
대표 도구
Spark, Informatica, Talend
dbt, BigQuery, Snowflake
추천 상황
규제 환경, PII 마스킹 필수
분석 유연성 우선, 클라우드 환경
2026년 기준 권장: 신규 프로젝트라면 ELT를 기본으로 선택하라. 클라우드 웨어하우스의 컴퓨팅 단가가 지속적으로 낮아지고 있고, dbt가 SQL 기반 변환을 테스트 가능하고 버전 관리 가능하게 만들었기 때문이다. ETL은 개인정보 보호 규제가 엄격한 금융·의료 도메인에서 원본 데이터를 웨어하우스에 올리지 못하는 경우에 여전히 유효하다.
Apache Airflow — 데이터 파이프라인 오케스트레이션의 표준
Airflow는 데이터 파이프라인의 '언제, 어떤 순서로, 무엇을 실행할지'를 관리하는 도구다. DAG(Directed Acyclic Graph)로 작업 의존성을 정의하고, 스케줄러가 지정된 시간에 실행하며, 실패 시 알림과 재시도를 처리한다.
Airflow가 필요한 시점:
cron 작업이 5개를 넘어서면서 의존성 관리가 복잡해질 때
파이프라인 실패 시 수동으로 재실행하고 있을 때
데이터 적재 순서가 보장되어야 할 때 (A 완료 후 B 실행)
파이프라인 실행 이력과 로그를 추적해야 할 때
Airflow DAG 예시 — 일일 매출 집계 파이프라인
# dags/daily_sales_pipeline.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data-team',
'retries': 2,
'retry_delay': timedelta(minutes=5),
'email_on_failure': True,
'email': ['data-team@company.com'],
}
with DAG(
'daily_sales_pipeline',
default_args=default_args,
schedule_interval='0 2 * * *', # 매일 새벽 2시
start_date=datetime(2026, 1, 1),
catchup=False,
tags=['sales', 'daily'],
) as dag:
extract_orders = PostgresOperator(
task_id='extract_orders',
postgres_conn_id='source_db',
sql='sql/extract_daily_orders.sql',
)
transform_sales = PythonOperator(
task_id='transform_sales',
python_callable=transform_sales_data,
)
load_warehouse = PostgresOperator(
task_id='load_warehouse',
postgres_conn_id='warehouse_db',
sql='sql/load_sales_fact.sql',
)
run_dbt_models = BashOperator(
task_id='run_dbt',
bash_command='cd /opt/dbt && dbt run --select sales_mart',
)
# 실행 순서 정의
extract_orders >> transform_sales >> load_warehouse >> run_dbt_models
Airflow 대안 비교:
Prefect: Python 네이티브, Airflow보다 설정이 간단. 소규모 팀에 적합
Dagster: 데이터 자산(Asset) 중심 패러다임. dbt 통합이 뛰어남
Mage.ai: 노트북 스타일 UI, 빠른 프로토타이핑에 유리
팀이 5명 이상이고, 파이프라인이 20개를 넘어간다면 Airflow가 안정적인 선택이다. 1~3명 팀이라면 Prefect나 Dagster가 운영 오버헤드를 줄여준다.
dbt로 데이터 변환을 코드처럼 관리하기
dbt(data build tool)는 SQL 기반 변환(T)을 소프트웨어 엔지니어링 방식으로 관리하는 도구다. SELECT 문만 작성하면 dbt가 CREATE TABLE/VIEW, 의존성 해결, 테스트, 문서화를 자동으로 처리한다.
dbt가 해결하는 문제:
수백 줄의 SQL 변환 로직이 Jupyter 노트북이나 스크립트에 흩어져 있는 상황
변환 로직의 버전 관리(Git)와 코드 리뷰가 불가능한 상황
데이터 정합성 테스트를 수동으로 하고 있는 상황
상류 테이블 변경 시 하류 테이블에 미치는 영향을 파악할 수 없는 상황
dbt 모델 예시 — 일일 매출 마트 테이블
-- models/marts/sales/daily_sales.sql
{{ config(
materialized='incremental',
unique_key='sale_date',
cluster_by=['sale_date']
) }}
WITH orders AS (
SELECT * FROM {{ ref('stg_orders') }}
{% if is_incremental() %}
WHERE order_date >= (SELECT MAX(sale_date) FROM {{ this }})
{% endif %}
),
payments AS (
SELECT * FROM {{ ref('stg_payments') }}
),
joined AS (
SELECT
o.order_date AS sale_date,
COUNT(DISTINCT o.order_id) AS total_orders,
COUNT(DISTINCT o.customer_id) AS unique_customers,
SUM(p.amount) AS total_revenue,
SUM(p.amount) / NULLIF(COUNT(DISTINCT o.order_id), 0) AS avg_order_value
FROM orders o
LEFT JOIN payments p ON o.order_id = p.order_id
WHERE p.status = 'completed'
GROUP BY 1
)
SELECT * FROM joined
dbt 테스트 — 데이터 품질 자동 검증:
unique: 특정 컬럼의 값이 중복되지 않는지 확인
not_null: NULL 값이 없는지 확인
accepted_values: 허용된 값 목록에 포함되는지 확인
relationships: 외래 키 참조 무결성 확인
dbt test 명령 하나로 모든 모델의 데이터 품질을 검증한다. CI/CD에 통합하면 PR 단계에서 데이터 정합성 문제를 잡을 수 있다.
dbt 워크플로우 — SQL 모델 작성 → 테스트 → 문서화 → 배포
데이터 웨어하우스 선택 — BigQuery vs Snowflake vs Redshift
항목
BigQuery
Snowflake
Redshift
과금 모델
스캔한 바이트 기준
컴퓨팅 크레딧 기준
노드 시간 기준
서버리스
완전 서버리스
준서버리스
Serverless 옵션
스토리지/컴퓨팅 분리
완전 분리
완전 분리
RA3에서 분리
무료 티어
월 1TB 쿼리 + 10GB 저장
$400 크레딧 (30일)
2개월 무료 체험
강점
ML 통합(Vertex AI), 비용 예측성
멀티클라우드, 데이터 공유
AWS 생태계 통합
추천
GCP 환경, ML 파이프라인
멀티클라우드, 데이터 마켓
AWS 올인 환경
한국 시장 기준 추천:
스타트업 (데이터 1TB 미만): BigQuery 무료 티어로 시작. 월 $0으로 시작 가능하고, 스케일업 시 비용 예측이 쉽다.
중견기업 (멀티클라우드): Snowflake가 적합. AWS·GCP·Azure 어디서든 동일하게 동작하고, 외부 데이터 공유(Data Clean Room)가 강점이다.
AWS 올인 기업: Redshift Serverless가 비용 효율적. S3 데이터 레이크와의 연동(Spectrum)이 자연스럽다.
데이터 엔지니어 전환 로드맵 — 백엔드에서 시작하기
백엔드 엔지니어가 데이터 엔지니어로 전환할 때 가장 큰 장점은 이미 SQL, API, 인프라 기초가 있다는 점이다. 추가로 익혀야 할 핵심 역량은 다음과 같다:
데이터 엔지니어 전환 12주 로드맵
# Phase 1 (Week 1-4): SQL 고급 + 데이터 모델링
- Window Functions (ROW_NUMBER, LAG, LEAD, SUM OVER)
- CTE(Common Table Expression) 활용 복잡 쿼리
- Star Schema / Snowflake Schema 설계
- BigQuery 또는 DuckDB로 실습
# Phase 2 (Week 5-8): 파이프라인 도구
- Airflow 설치 → DAG 작성 → 스케줄링
- dbt 프로젝트 구성 → 모델 → 테스트
- Python으로 API 데이터 수집 스크립트 작성
- Docker로 Airflow + dbt 로컬 환경 구성
# Phase 3 (Week 9-12): 실전 프로젝트
- 공개 데이터셋으로 End-to-End 파이프라인 구축
(수집 → 적재 → 변환 → 대시보드)
- Metabase 또는 Superset으로 시각화
- GitHub에 프로젝트 공개 (README, 아키텍처 다이어그램)
- 데이터 품질 테스트(dbt test) + CI/CD 통합