트래픽이 초당 50건일 때는 아무 문제 없던 API가, 프로모션 하루 만에 초당 3,000건을 맞으면 DB 커넥션 풀이 고갈되고 전체 서비스가 멈춘다. 이 글은 Rate Limiting의 핵심 알고리즘 4가지를 코드 수준에서 분석하고, 단일 서버에서 Redis 기반 분산 환경까지 프로덕션에서 실제로 동작하는 구현 전략을 다룬다. Rate Limiting은 단순한 트래픽 제한이 아니다.
트래픽이 초당 50건일 때는 아무 문제 없던 API가, 프로모션 하루 만에 초당 3,000건을 맞으면 DB 커넥션 풀이 고갈되고 전체 서비스가 멈춘다. 이 글은 Rate Limiting의 핵심 알고리즘 4가지를 코드 수준에서 분석하고, 단일 서버에서 Redis 기반 분산 환경까지 프로덕션에서 실제로 동작하는 구현 전략을 다룬다.
단순히 "429 Too Many Requests를 반환하면 된다"는 수준이 아니라, 어떤 알고리즘을 왜 선택해야 하는지, 분산 환경에서 race condition은 어떻게 막는지, 클라이언트에게 어떤 헤더를 줘야 하는지까지 설계 판단에 필요한 전부를 정리했다.
※ 이 글은 2026년 3월 기준, IETF RFC 6585·RFC 9110 및 Cloudflare·Stripe·GitHub API 문서를 참조하여 작성됐습니다.
Rate Limiting이 없으면 무엇이 무너지는가
Rate Limiting은 단순한 트래픽 제한이 아니다. 프로덕션 API에서 Rate Limiting이 없으면 세 가지가 동시에 무너진다.
첫째, 가용성이 무너진다. 하나의 클라이언트가 초당 수천 건의 요청을 보내면 DB 커넥션 풀, 메모리, CPU가 해당 요청에 점유된다. 정상 사용자의 요청은 큐에 쌓이다가 타임아웃으로 실패한다. 이것은 의도적인 DDoS가 아니어도 발생한다 — 버그가 있는 클라이언트 하나면 충분하다.
둘째, 비용이 무너진다. 서버리스 환경에서는 요청 수가 곧 비용이다. AWS Lambda + API Gateway 조합에서 악성 봇이 하루 1,000만 건을 쏘면 예상치 못한 수백 달러가 청구된다. Stripe는 이런 시나리오를 막기 위해 기본 Rate Limit을 모든 엔드포인트에 적용한다.
셋째, 공정성이 무너진다. 멀티테넌트 SaaS에서 한 테넌트가 API를 독점하면 다른 테넌트의 SLA가 위반된다. Rate Limiting은 자원을 공정하게 배분하는 메커니즘이기도 하다.
트래픽 급증 시 Rate Limiting 유무에 따른 p99 응답 시간 차이 (출처: Cloudflare Blog)
4가지 핵심 알고리즘과 선택 기준
Rate Limiting 알고리즘은 크게 4가지로 나뉜다. 각각의 특성이 다르기 때문에 서비스 유형에 따라 선택이 달라진다.
알고리즘
원리
장점
단점
적합한 시나리오
Fixed Window
1분 단위로 카운터 초기화
구현 단순
경계 시점 2배 버스트
내부 API, 관리자 도구
Sliding Window Log
요청 타임스탬프 기록
정확한 제한
메모리 사용량 높음
과금 API, 정밀 제어
Sliding Window Counter
이전·현재 윈도우 가중 평균
메모리 효율 + 정확도
근사치(오차 ~1%)
대부분의 Public API
Token Bucket
일정 속도로 토큰 충전, 요청 시 소모
버스트 허용 + 평균 제한
파라미터 튜닝 필요
Stripe, AWS, 대부분의 SaaS
실무에서 가장 많이 쓰이는 것은 Sliding Window Counter와 Token Bucket이다. Fixed Window는 구현이 간단하지만, 윈도우 경계(예: 59초와 01초)에서 짧은 시간 안에 허용량의 2배가 통과할 수 있다. Sliding Window Log는 정확하지만, 요청마다 타임스탬프를 저장해야 해서 초당 수만 건 이상의 API에서는 메모리 부담이 크다.
Token Bucket 알고리즘을 코드로 이해하기
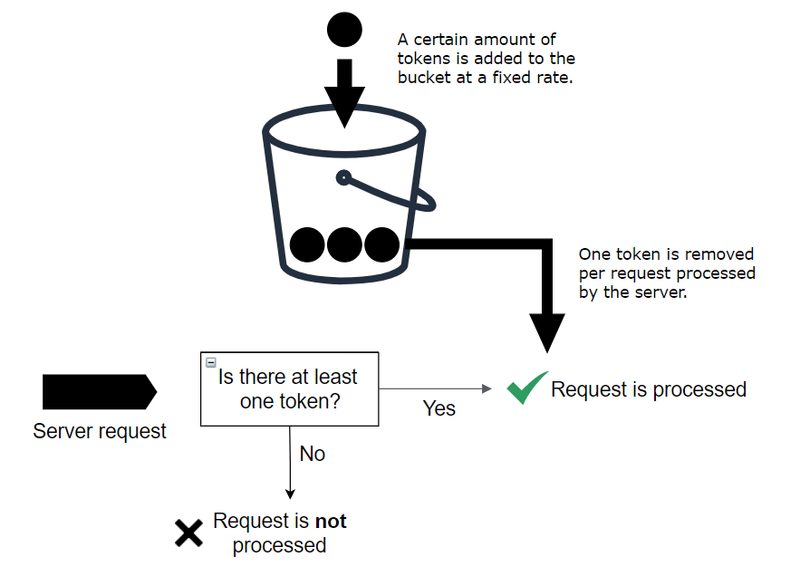
Token Bucket은 Stripe, AWS, GitHub API가 채택한 알고리즘이다. 핵심 개념은 간단하다: 버킷에 토큰이 일정 속도로 채워지고, 요청이 올 때마다 토큰 1개를 소모한다. 토큰이 없으면 요청이 거부된다. 버킷 용량(capacity)이 버스트 허용량이 되고, 충전 속도(refill rate)가 평균 요청 속도가 된다.
예를 들어 capacity=100, refill rate=10/초라면: 평소에는 초당 10건씩 처리하되, 버킷이 가득 찬 상태에서는 순간적으로 100건까지 처리할 수 있다. 이 "버스트 허용"이 Token Bucket의 핵심 장점이다.
위 코드는 단일 프로세스에서 동작하는 가장 기본적인 구현이다. tryConsume()이 호출될 때마다 경과 시간에 비례하여 토큰을 충전하고, 1개를 소모한다. 실무에서 주의할 점은 Map의 메모리 누수다 — 접속이 끊긴 IP의 버킷이 계속 남아있으면 메모리가 무한 증가한다. 반드시 TTL 기반 정리 로직을 추가해야 한다.
Redis로 분산 환경 Rate Limiting 구현하기
서버가 2대 이상이면 인메모리 방식은 의미가 없다. 서버 A에서 50건, 서버 B에서 50건을 각각 허용하면 실제로는 100건이 통과한다. 분산 환경에서는 공유 저장소가 필요하고, Redis가 사실상 표준이다.
핵심 과제는 원자성(atomicity)이다. "현재 카운터 읽기 → 한도 비교 → 카운터 증가"를 3단계로 실행하면, 두 서버가 동시에 읽기를 수행한 뒤 둘 다 통과시키는 race condition이 발생한다. Redis에서는 Lua 스크립트를 써서 이 전체 과정을 하나의 원자적 연산으로 실행한다.
Redis Lua 스크립트 — Sliding Window Counter (원자적 실행)
-- KEYS[1]: rate limit key (e.g., "rl:user:42")
-- ARGV[1]: window size in seconds
-- ARGV[2]: max requests per window
-- ARGV[3]: current timestamp in ms
local key = KEYS[1]
local window = tonumber(ARGV[1]) * 1000
local limit = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
-- Remove expired entries
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)
-- Count current window requests
local count = redis.call('ZCARD', key)
if count < limit then
redis.call('ZADD', key, now, now .. ':' .. math.random(1000000))
redis.call('PEXPIRE', key, window)
return {1, limit - count - 1} -- allowed, remaining
else
return {0, 0} -- denied, 0 remaining
end
이 Lua 스크립트는 Redis의 Sorted Set을 활용한 Sliding Window Log 구현이다. ZREMRANGEBYSCORE로 윈도우 밖의 요청을 제거하고, ZCARD로 현재 윈도우 내 요청 수를 세고, 한도 미만이면 새 요청을 추가한다. 전체가 Redis 서버 내에서 원자적으로 실행되므로 race condition이 없다.
프로덕션에서는 이 스크립트를 Node.js의 ioredis 라이브러리로 호출한다:
Node.js에서 Redis Lua 스크립트 호출 — ioredis 사용
import Redis from 'ioredis';
const redis = new Redis(process.env.REDIS_URL);
const SLIDING_WINDOW_SCRIPT = `
local key = KEYS[1]
local window = tonumber(ARGV[1]) * 1000
local limit = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)
local count = redis.call('ZCARD', key)
if count < limit then
redis.call('ZADD', key, now, now .. ':' .. math.random(1000000))
redis.call('PEXPIRE', key, window)
return {1, limit - count - 1}
else
return {0, 0}
end
`;
async function checkRateLimit(userId, windowSec = 60, maxReq = 100) {
const key = `rl:${userId}`;
const now = Date.now();
const [allowed, remaining] = await redis.eval(
SLIDING_WINDOW_SCRIPT, 1, key, windowSec, maxReq, now
);
return { allowed: allowed === 1, remaining };
}
분산 Rate Limiting 아키텍처: 모든 서버가 Redis의 Lua 스크립트를 통해 원자적으로 카운팅한다 (출처: 저자 작성)
클라이언트에게 알려줘야 할 응답 헤더
Rate Limiting은 서버만의 문제가 아니다. 클라이언트가 자신의 남은 할당량을 알아야 재시도 로직을 설계할 수 있다. IETF에서는 RateLimit 헤더 표준을 제안하고 있고(draft-ietf-httpapi-ratelimit-headers), GitHub·Stripe·Slack 등 주요 API는 이미 유사한 헤더를 사용한다.
Retry-After 헤더는 429 응답에서 필수다. 이 헤더가 없으면 클라이언트는 즉시 재시도하고, 이는 상황을 악화시킨다. Stripe의 공식 SDK는 Retry-After 값을 읽어서 지수 백오프(exponential backoff)를 적용하고, 최대 3회까지만 재시도한다.
엔드포인트별·플랜별 차등 제한 설계
모든 엔드포인트에 동일한 Rate Limit을 적용하는 것은 실무에서 통하지 않는다. 읽기(GET)와 쓰기(POST/PUT/DELETE)의 서버 부하가 다르고, 무료 플랜과 유료 플랜의 할당량도 달라야 한다.
실전에서 효과적인 패턴은 3계층 구조다:
글로벌 리밋 — 전체 API에 대해 IP당 초당 50건. DDoS 수준의 트래픽을 1차 차단한다.
사용자 리밋 — 인증된 사용자별 분당 100~1,000건 (플랜에 따라 차등). 대부분의 정상 사용은 이 계층에서 처리된다.
엔드포인트 리밋 — 비용이 높은 특정 엔드포인트(예: AI 추론, PDF 생성, 대량 검색)에 추가 제한. 분당 10건 수준.
이 3개 계층은 독립적으로 동작한다. 사용자 리밋 안에 있어도, 특정 엔드포인트 리밋에 걸리면 429를 반환한다. 응답에는 어떤 계층에서 제한됐는지를 명시하는 것이 좋다.
플랜
글로벌 (IP)
사용자
AI 추론 엔드포인트
대량 검색
Free
50/초
100/분
5/분
10/분
Pro
50/초
500/분
30/분
60/분
Enterprise
200/초
2,000/분
120/분
300/분
프로덕션에서 자주 겪는 5가지 함정
1. Redis 단일 장애점(SPOF) Rate Limiting을 Redis에 의존하면, Redis가 죽었을 때 모든 요청이 차단되거나 모든 요청이 통과한다. 프로덕션에서는 Redis 장애 시 "일단 통과(fail-open)" 정책을 기본으로 설정하고, Redis Sentinel 또는 Cluster로 고가용성을 확보해야 한다. Rate Limiting 실패 때문에 전체 서비스가 멈추면 본말이 전도된 것이다.
2. 시간 동기화 문제 Sliding Window는 타임스탬프에 의존한다. 서버 간 시계가 수십 초 어긋나면 윈도우 계산이 틀어진다. 모든 서버에서 NTP를 활성화하고, 가능하면 Redis 서버의 시간을 기준으로 삼는다(Lua 스크립트 내에서 redis.call('TIME') 사용).
3. API Key 누락 시 IP 폴백 인증되지 않은 요청에 IP 기반 Rate Limiting을 적용하면, 같은 NAT 뒤의 수백 명이 하나의 IP로 잡힌다. 기업 사무실, 대학교, 카페 Wi-Fi에서 이 문제가 발생한다. IP 기반 리밋은 글로벌 계층(DDoS 방어)에만 사용하고, 비즈니스 로직 리밋은 반드시 사용자 식별자 기반으로 적용해야 한다.
4. 429 응답에 정보가 없음 {"error": "rate limited"}만 반환하면 클라이언트 개발자는 원인을 알 수 없다. 어떤 계층에서 제한됐는지, 언제 재시도하면 되는지, 한도를 올리려면 어떻게 해야 하는지를 응답 본문에 포함해야 한다.
5. Rate Limit 키 설계 실수 키를 user_id로만 설정하면 한 사용자가 여러 클라이언트(웹, 모바일, CLI)를 동시에 쓸 때 불공정하게 제한된다. 반대로 user_id:endpoint로 너무 세분화하면 Redis 키가 폭증한다. 적절한 키 설계는 user_id:method:resource_type 수준이다.
Stripe는 429 응답에 제한 유형, 재시도 시간, 한도 상향 방법까지 안내한다 (출처: Stripe API Docs)
직접 구현 vs 매니지드 서비스 판단 기준
Rate Limiting을 직접 구현할 것인지, 인프라 레벨에서 처리할 것인지는 서비스 규모와 요구사항에 따라 달라진다.
직접 구현이 적합한 경우: 사용자별·엔드포인트별 세밀한 제어가 필요할 때, 비즈니스 로직과 결합된 동적 리밋(예: 결제 상태에 따라 한도 변경)이 필요할 때, 429 응답 본문을 커스텀해야 할 때.
매니지드 서비스가 적합한 경우: 글로벌 DDoS 방어 수준의 Rate Limiting, L7 레벨의 봇 감지, 수십만 rps 규모의 처리가 필요할 때.
방식
도구
장점
단점
직접 구현
Redis + Lua, express-rate-limit
세밀한 제어, 비용 절감
운영 부담, 장애 대응 직접
API Gateway
AWS API Gateway, Kong, Traefik
코드 변경 없음, 중앙 관리
세밀한 커스텀 어려움
CDN/WAF
Cloudflare, AWS WAF, Akamai
글로벌 엣지, DDoS 방어
비즈니스 로직 반영 불가
현실적인 권장 조합은 2단계 방어다. 1차로 Cloudflare나 AWS WAF에서 IP 기반 글로벌 리밋을 적용하고, 2차로 애플리케이션 레벨에서 사용자별·엔드포인트별 비즈니스 리밋을 Redis로 처리한다. 대부분의 SaaS는 이 조합으로 충분하다.